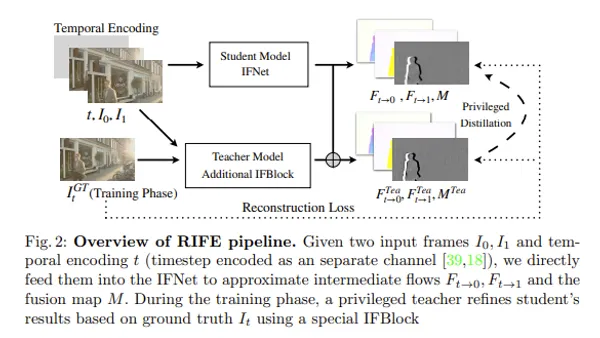
今回はTextual Inversion(embedding)を紹介しようと思います。Textual InversionとはStable Diffusionの出力を言語の面から制御する手法であり、それを使うことで好きな絵柄であったり、構成であったりに出力を寄せることが可能になります。つまりは自分が出したい絵が出しやすくなるということです。
ここだけ聞くとLoRAと何が違うのかと考える方もいらっしゃると思いますが、その通りTextual InversionとLoRAがやろうとしてることはほぼ同じです。どういう切り口で制御しようとしているかが異なっており、LoRAはアーキテクチャの面から、Textual Inversionは入力となるプロンプト(もっといえばText Encoder)の面から出力を制御しようとしています。
今回の記事ではTextual Inversionの仕組みについて調べてみようと思います。
embeddingとは
Textual Inversionについての説明に入る前に、この論文で大事になるembeddingについて説明を挟みます。
embeddingの概要
Embeddingとは、言葉(プロンプト)を数学的なベクトルに変換したもので、これによりベースモデルがプロンプトの意味を理解できるようになります。例えば、「猫」という言葉をコンピュータが理解できる数値のリストに変換することで、他の言葉と比べて似ているかどうかを数値的に比較できるようになったりします。
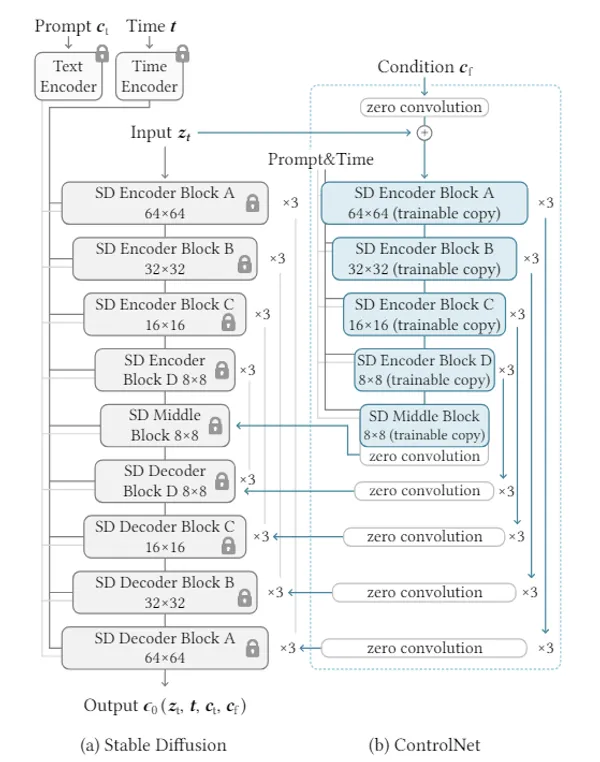
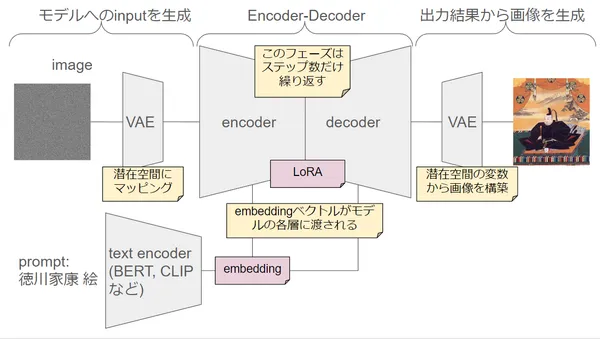
Stable Diffusionモデルでいうと、下の図にあるようにText Encoderから出力されるベクトルがembeddingにあたります。
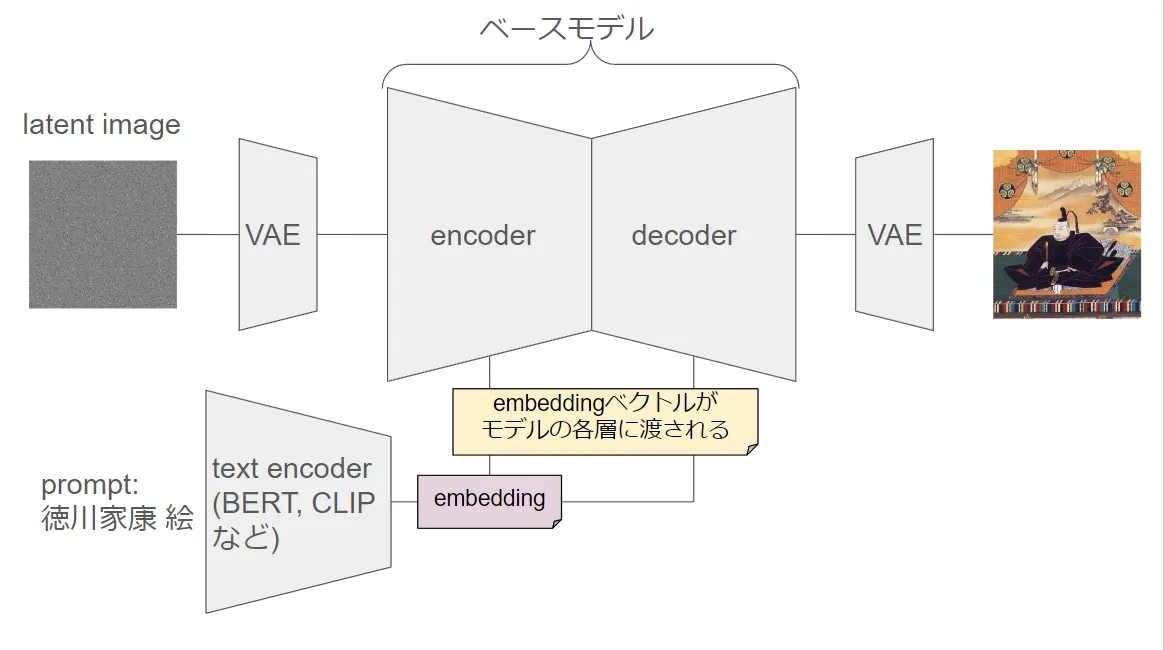
embeddingの処理
Stable Diffusionモデルでは、embeddingは通常、以下のプロセスを通じて生成、処理されます。
- プロンプトの入力:
- まず、ユーザーが「猫の絵を描いて」といったプロンプト(指示)を入力します。
- テキストエンコーダの処理:
- プロンプトはテキストエンコーダ(例えば、BERTやCLIP)に送られます。テキストエンコーダは、プロンプトの言葉を数学的な数値のリスト、つまり「言語ベクトル(embedding)」に変換します。言語ベクトルは、コンピュータが言葉の意味を理解しやすくするためのものです。
- 言語ベクトルの生成:
- テキストエンコーダは、学習済みの重み(モデルが多くのデータで学習した情報)を使って、プロンプトの内容を反映したembeddingを生成します。例えば、「猫」という言葉が含まれている場合、その言葉に関連する特徴を持つ数値リストが生成されます。
- ベースモデルへの入力:
- 生成されたembeddingは、Stable Diffusionなどのベースモデルに入力されます。このベースモデルは、embeddingを解釈して、指示に基づいた画像を生成します。
Textual Inversionについて

Text-to-image models offer unprecedented freedom to guide creation through natural language. Yet, it is unclear how such freedom can be exercised to generate images of specific unique concepts, modify their appearance, or compose them in new roles and novel scenes. In other words, we ask: how can we use language-guided models to turn our cat into a painting, or imagine a new product based on our favorite toy? Here we present a simple approach that allows such creative freedom. Using only 3-5 images of a user-provided concept, like an object or a style, we learn to represent it through new "words" in the embedding space of a frozen text-to-image model. These "words" can be composed into natural language sentences, guiding personalized creation in an intuitive way. Notably, we find evidence that a single word embedding is sufficient for capturing unique and varied concepts. We compare our approach to a wide range of baselines, and demonstrate that it can more faithfully portray the concepts across a range of applications and tasks. Our code, data and new words will be available at: https://textual-inversion.github.io

Textual Inversionの概要
Textual Inversionは、Text Encoderを学習させることで、生成されるembeddingの方向を変える手法です。(Text Encoderの位置は下記の画像を参照してください。)つまり、新しい概念や言葉を学習して、それに合った新しい言語ベクトルを生成し、ベースモデルが解釈可能な形にします。こうして、モデルは新しい言葉や概念を使った画像を生成できるようになります。

Textual Inversionの学習方法
- データ収集 (Data Collection):
- 特定の概念を持つ3〜5枚の画像とその対応するテキスト説明を収集します。例えば、「徳川家康の肖像画」とその説明文を集めます。
- 埋め込み生成 (Embedding Generation):
- 新しいトークンを既存のテキストエンコーダ(例えばCLIP)に追加します。
- 画像とテキストのペアを使用して、新しいトークンのembeddingを学習します。
- 埋め込みの最適化 (Embedding Optimization):
- 生成されたembeddingをモデルの既存のembedding空間と一致させるように最適化(学習)します。
- (この時元のモデルの重みは凍結したままで、embeddingのみ学習させます)
評価結果
学習に使用する画像を変えるだけで出力が変化しているのがわかります。

最後に
Textual Inversionは、Stable Diffusionを活用する上で非常に有用な技術です。この手法を理解し、実際に応用することで、自分が思い描く通りの画像を生成することが可能になります。LoRAとの違いを把握し、適切な手法を選ぶことで、さらに高精度な結果を得ることができます。この記事を通じて、Textual Inversionの基本的な仕組みについての理解が深まれば幸いです。
Textual Inversionを試す方法については以下の記事で説明をしています。試したい方はこちらを読んでみてください。

>-
Stable Diffusion周りで読んだ論文は以下の記事でまとめているので、興味ある方はぜひご活用ください。
Stable Diffusion関連の論文解説記事のリンク集。画像生成・動画生成の基礎モデルから応用技術まで論文ベースで解説。