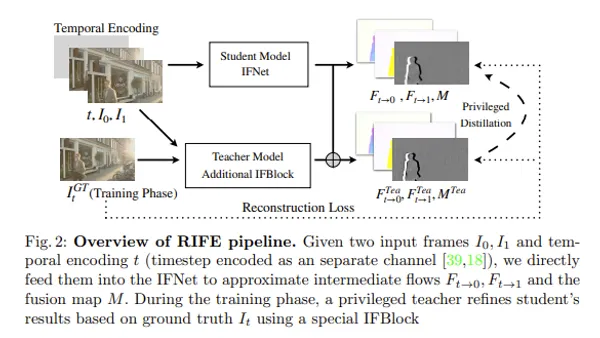
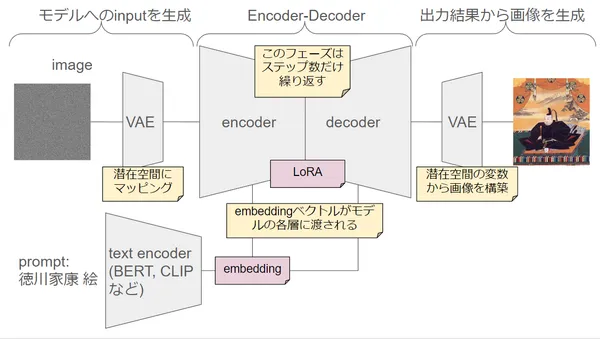
今回はAnimateDiffを紹介します。AnimateDiffとは画像生成モデル(Stable Diffusion)を拡張し、動画を生成できるように学習させたモデルです。ほとんど元の画像生成モデルと変わらないので、かなり軽量に動画を生成することができます。AnimateDiffは、ユーザーが指定するパラメータや条件に基づいてアニメーションをカスタマイズできる機能を持ちます。こういった技術の研究がさらに進んでいけば、アニメーションスタジオや個人クリエイターが迅速かつ効率的に高品質なアニメーションを制作することにつながるため、ゲーム開発や広告制作など多岐にわたる分野で期待がされています。
今回の記事ではAnimateDiffの仕組みについて調べてみようと思います。
AnimateDiffについて

With the advance of text-to-image (T2I) diffusion models (e.g., Stable Diffusion) and corresponding personalization techniques such as DreamBooth and LoRA, everyone can manifest their imagination into high-quality images at an affordable cost. However, adding motion dynamics to existing high-quality personalized T2Is and enabling them to generate animations remains an open challenge. In this paper, we present AnimateDiff, a practical framework for animating personalized T2I models without requiring model-specific tuning. At the core of our framework is a plug-and-play motion module that can be trained once and seamlessly integrated into any personalized T2Is originating from the same base T2I. Through our proposed training strategy, the motion module effectively learns transferable motion priors from real-world videos. Once trained, the motion module can be inserted into a personalized T2I model to form a personalized animation generator. We further propose MotionLoRA, a lightweight fine-tuning technique for AnimateDiff that enables a pre-trained motion module to adapt to new motion patterns, such as different shot types, at a low training and data collection cost. We evaluate AnimateDiff and MotionLoRA on several public representative personalized T2I models collected from the community. The results demonstrate that our approaches help these models generate temporally smooth animation clips while preserving the visual quality and motion diversity. Codes and pre-trained weights are available at https://github.com/guoyww/AnimateDiff.

AnimateDiffの概要
AnimateDiffはStable Diffusionモデルをベースとして拡張することで、動画生成を可能にしたモデルです。Stable Diffusionは、画像生成タスクで高精度な結果をもたらす強力な拡散モデルであり、ノイズの逐次的な除去を通じてデータを再構築するプロセスを特徴としています。(ここら辺は以下の記事で説明しています)

>-
AnimateDiffはこのStable Diffusionモデルを拡張し、連続するフレーム間の時間的な一貫性と滑らかさを維持しつつ、高品質なアニメーションを生成する能力を持っています。以下でどのような手法でこれが実現されているかを説明します。
AnimateDiffの特徴
AnimateDiffではStable Diffusionモデルの拡張と学習方法の工夫の二つのアプローチで実現されています。まず、
モデルの拡張
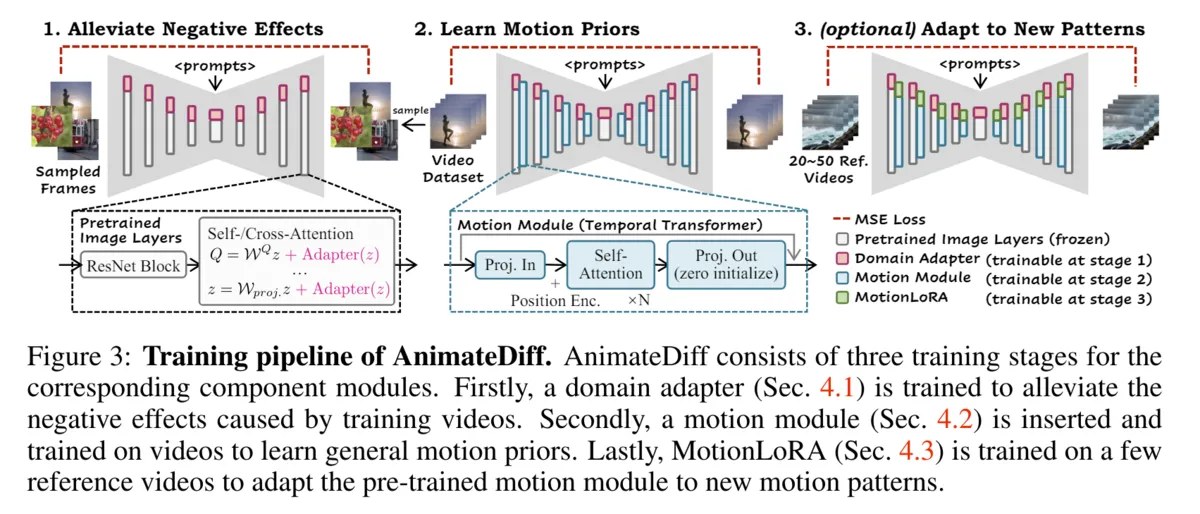
Domain Adapter, Motion Module, Motion LoRAの三種類の拡張を使ってStable Diffusionを動画用に改造します。
Domain Adapter
- Domain AdapterはいわゆるLoRAです。LoRAと同様の構造を持ちドメイン間の分布の違い(今回でいえば画像用データセットと動画用データセットの質の違い)を埋めるためにStable Diffusionモデルに追加され学習されます。
- これにより、異なるアニメーションスタイルやフレーム間の一貫性を保ちながら、異なるデータセット間の情報を効果的に統合できるそうです。
※LoRAが何者かがわからない方は下の記事で説明しているのでよかったら読んでみてください。
>-
モーションモジュール
- 時系列の一貫した動きと変化を学習するために、トランスフォーマーを組み込んだモジュールを追加します。これにより、スムーズな動きを実現しています。
- モーションモジュールはStable Diffusionの各層の後ろに直列に追加されます。
- このモジュールは5Dに変換された入力を受け取り、筆者が提案するTemporal Transformerで処理を行います。処理を行った後は再度テンソルの形を元に戻して、Stable Diffusionの層に渡します。
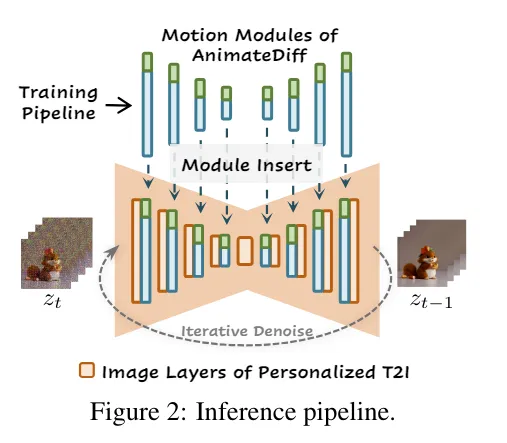
Motion LoRA
- 端的にいってしまうと、Motion Moduleの層に追加するLoRAです。特に特徴的なこともないです。
学習方法
AnimateDiffは次の3段階でモデルを途中で拡張しながら学習を行います。これにより、画像用に学習されたモデルが持つ空間的情報を利用しながら、段階的に時間軸の情報をモデルに学習させていくことができます。
- 各層にDomain Adapterを追加し、追加した部分のみを学習させます。(元モデルのweightは固定)
- 画像用に学習されたモデルを動画のデータセット用に調整する
- 各層にモーションモジュールを追加し学習します。
- モーションを学習する
- (オプショナル)モデルの各層にMotion LoRAを追加し、数本の動画で特定の動きを学習します。
最後に
AnimateDiffは、Stable Diffusionモデルの強力な画像生成能力を活用しつつ、動画生成を可能にする新たな技術です。Domain Adapter、Motion Module、Motion LoRAなどの拡張と、工夫された学習方法により、高品質なアニメーションを軽量に生成することができるようになりました。今後、このような技術がさらに進化し、より多様なアニメーションスタイルや高精度な動きを実現できるようになることを期待しています。
以下の記事では実際に生成してみた結果を載せているので、良かったら見ていってください。
>-
Stable Diffusion周りで読んだ論文は以下の記事でまとめているので、興味ある方はぜひご活用ください。
Stable Diffusion関連の論文解説記事のリンク集。画像生成・動画生成の基礎モデルから応用技術まで論文ベースで解説。