Stable Diffusion周りの論文解説記事です。
画像生成周り
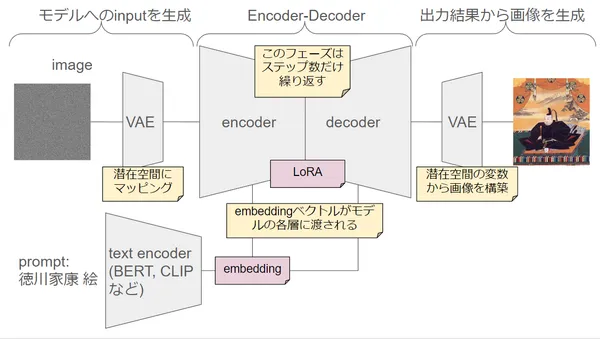
Stable Diffusion
みんな大好きStable Diffusionモデル。Text Encoder, UNet, VAEを組み合わせたモデルになっています。

【Stable Diffusion】画像生成モデルの仕組みを理解する
>-
Stable Diffusion 3
Stable Diffusionモデルを最新技術にアップデートしたものです。UNetではなくMMDiTというTransformerベースのモデルに変更するとともに、ノイズスケジュールを最適化する、TextEncoderを3つに増やすなど少しTweakが入っています。
Stable Diffusion 3論文読み:ついにUNetを卒業したようです
>-
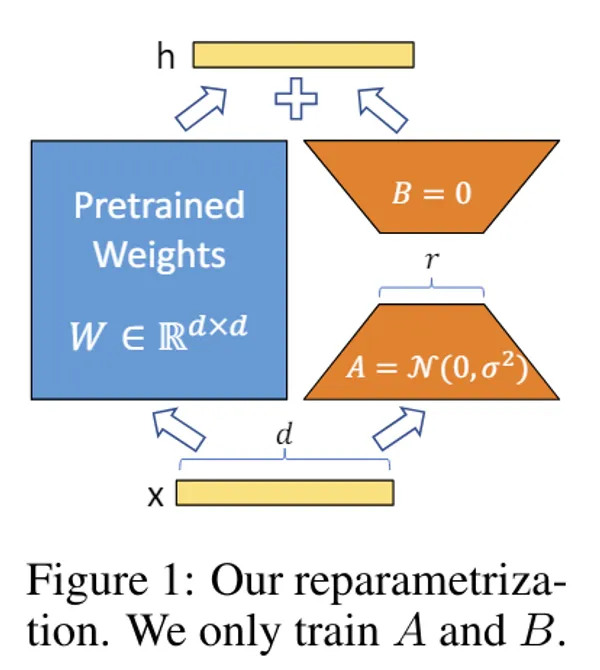
LoRA
みんな大好きLoRA。モデルの拡張パーツともいえるもので、少しパラメータを増やすだけでモデルの追加学習が行えます。(元々は言語モデル用に提案されたもの)
LoRA(Low-Rank Adaptation)とは?大規模モデルを低コストでファインチューニングする手法とメリット
>-
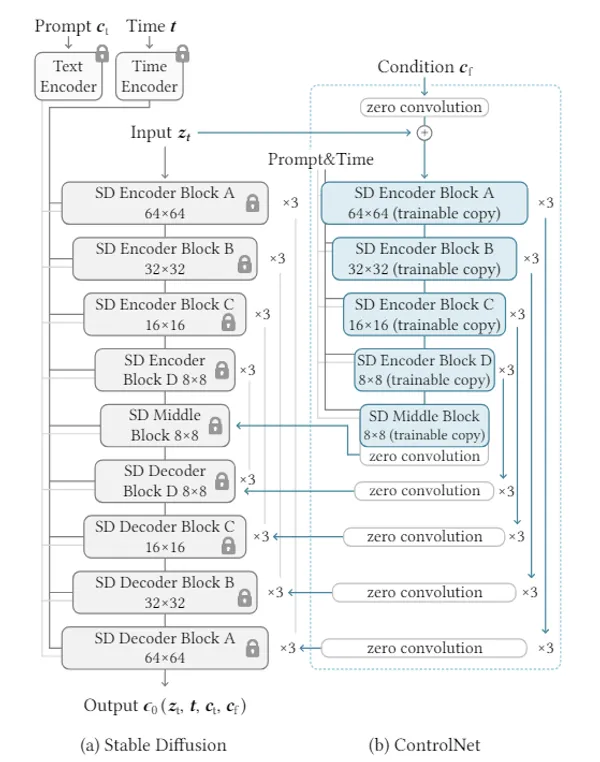
ControlNet
ControlNetは、画像に映る人物の姿勢を制御するためのモデル拡張です。UNetを2重にして片方に姿勢データを学習させるようにしています。
Stable Diffusionモデルで姿勢を学習・制御するControlNetの基礎
>-
Textual Inversion
UNetではなくText Encoderをいじる手法です。本体であるUNetの外側をいじるため、比較的効果は弱めですが、パラメータを増やす必要がない、学習もUNetをいじるより容易といった利点があります。
Textual Inversionのわかりやすい解説:Stable Diffusionの制御手法
>-
IPAdapter
Text Encoderと並列にImage Encoderを用意し、画像プロンプトを受け取れるようにする手法です。
IPAdapterの簡単解説:画像をプロンプトとして使用できる!?【Stable Diffusion】
>-
動画生成周り
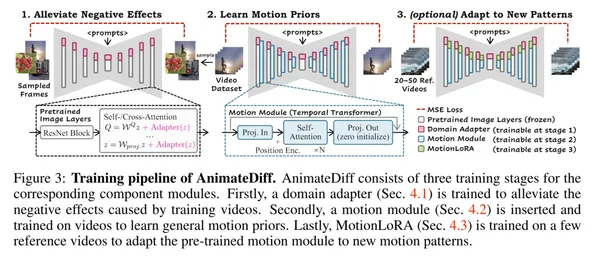
AnimateDiff
Stable Diffusionに時間軸の学習ができるように層を追加したモデルです。
AnimateDiff: Stable Diffusionを拡張した軽量動画生成モデルの仕組み
>-
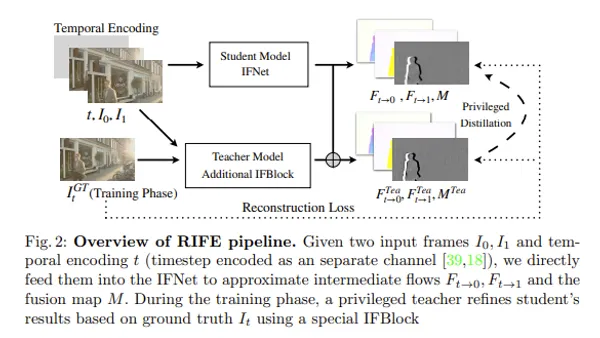
RIFE
中間フレームを生成し、動画のフレームレートを向上させる技術です。
動画のフレームレートを上げる技術:RIFEとそのアーキテクチャ
>-
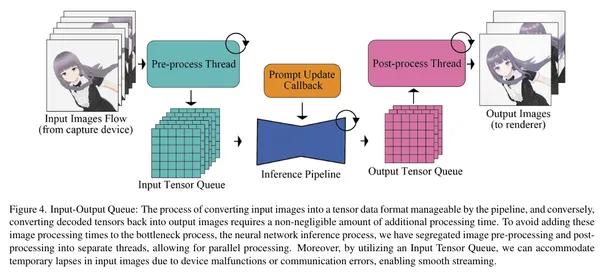
Stream Diffusion
パイプライン処理やその他高速化のためのテクニックを導入し、超高速に画像生成を行えるようにしたモデルです。RTX 4090で最大91.07fpsとのこと。
Stream Diffusion: リアルタイムな動画生成を可能にする新技術
>-