AI & Creativity
4分で読了
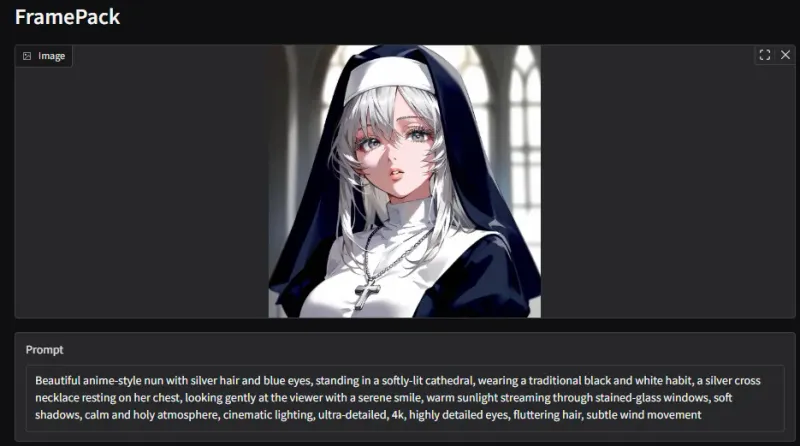
VRAM6GBでも動く!動画生成AI「FramePack」のデモを試してみた
「FramePack」はVRAM使用量を大幅に削減した動画生成AIモデルです。本記事ではRTX3050(8GB)を用いて実際に公式デモを試し、動作環境やセットアップ方法、生成品質について詳しく解説します。動画生成の軽量化に興味がある方必見です。
12 記事
「FramePack」はVRAM使用量を大幅に削減した動画生成AIモデルです。本記事ではRTX3050(8GB)を用いて実際に公式デモを試し、動作環境やセットアップ方法、生成品質について詳しく解説します。動画生成の軽量化に興味がある方必見です。
画像生成AI「Stable Diffusion」における代表的な3つのimage2image手法(Latent Image、ControlNet、IPAdapter)の特徴を徹底比較。各アプローチの仕組みやワークフロー構成、生成結果の違い、メリット・デメリットを初心者向けに解説します。
画像生成AIでよくある顔崩れを自動解決する「Face Detailer」を解説。Stable DiffusionのGUI環境「ComfyUI」と専用拡張機能を使い、画像生成後のワークフローに組み込んで顔の手直しを簡単に行う手順と生成結果を紹介します。
ComfyUIとLCM-LoRAを活用し、ローカル環境で落書きからAI画像をリアルタイム生成する方法を解説!必要なカスタムノードの導入からワークフローの設定、Auto Queue機能を使った動的な画像生成プロセスまで詳しく紹介します。akuma.aiのような体験を自分のPCで再現しましょう。
無料のペイントソフト Krita と Stable Diffusion 拡張(krita-ai-diffusion)を組み合わせ、落書きからAI画像をリアルタイム生成する手順を解説!プラグインの導入からサーバー設定、Live Preview機能を使った直感的な画像生成方法まで初心者向けにガイドします。
Stable Diffusion 3は、CLIPとT5を組み合わせた新しいText Encoderや、DiTアーキテクチャの導入で大幅に進化しました。新しいノイズスケジューラーにより、生成性能が向上し、txt2imgで最先端モデルを超える性能を実現。簡単に論文の内容を説明します。
ComfyUIを使ったStableDiffusionによるInpaint技術の手順を詳しく解説。画像の特定部分をマスクし、新たな要素を追加する方法をステップバイステップで説明します。生成結果も掲載しています。
この記事では、ComfyUIを使って、Stable DiffusionのOutpaintを行う手順を紹介します。Outpaintを使用することで、自分で描かずとも、画像の外側に新しい内容を追加することができます。
ComfyUIを使ってStable Diffusionでembeddingを使用する方法を紹介します。好きなembeddingを使用した実例とその効果の違いを画像で比較し、より良い生成結果を得るためのポイントも解説します。
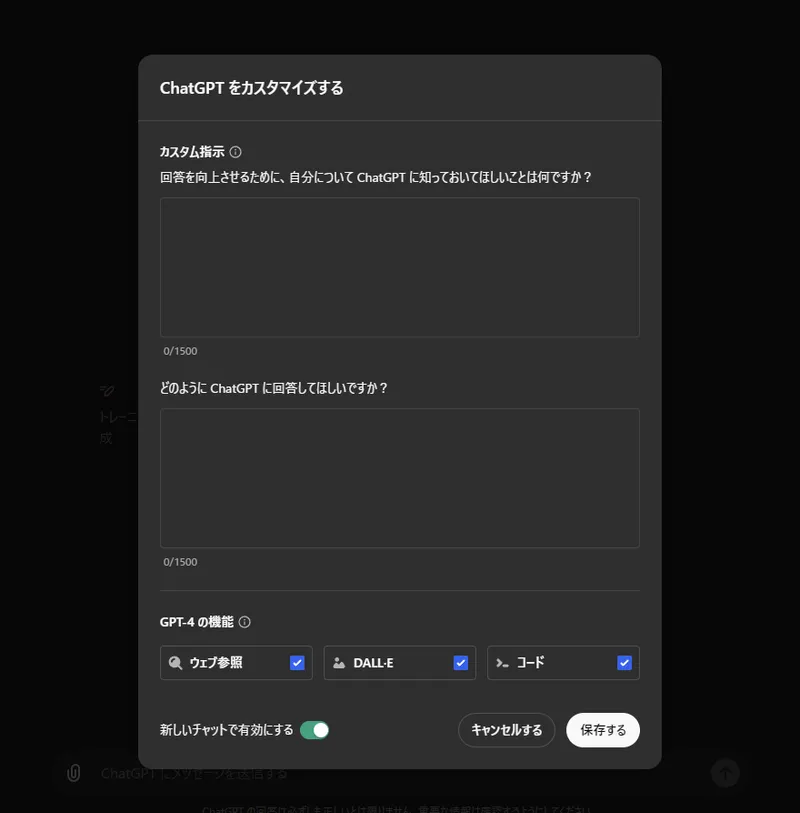
この記事では、ChatGPTのCustom Instructions機能を活用し、応答の正確性向上や特定のコマンドの覚えさせ方を解説します。各種カスタマイズ例を紹介し、日常的なやり取りをより効率的にするためのヒントを提供。初心者にもわかりやすく、ステップバイステップで説明しています。
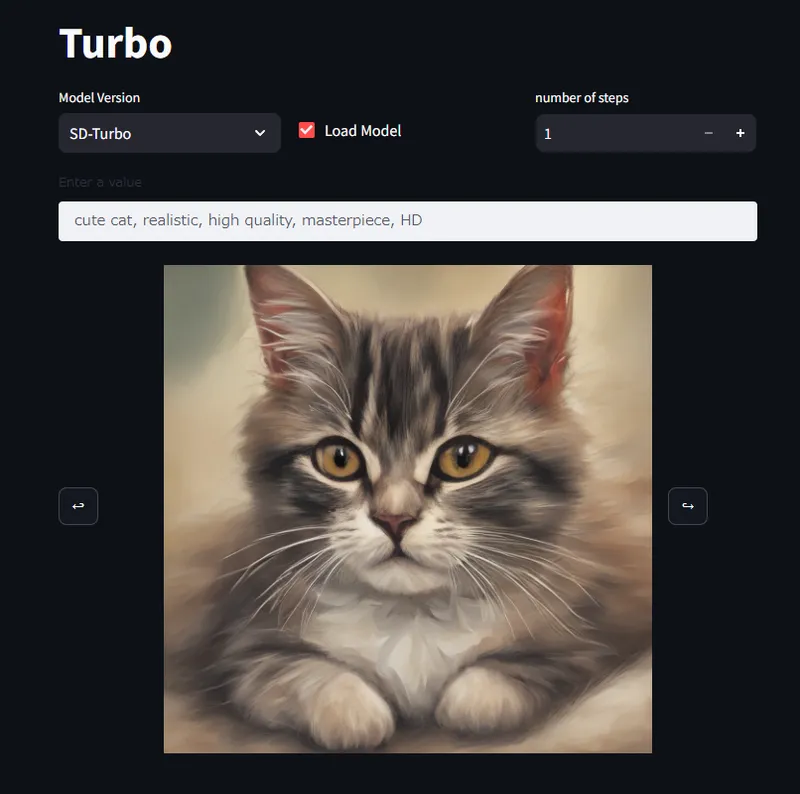
この記事では、SD-TurboおよびSDXL-Turboのモデル構造と機能を解説します。さらに、ローカル環境でこれらのモデルを試すための具体的な手順を紹介。必要なツールのインストールからDockerを使ったデモの設定まで、初心者でも理解しやすいように説明しています。
「Stable Video Diffusion」は有名なStable Diffusionを動画用に拡張したimage2videoモデルで、かなり高精度に動画を生成することができます。記事では、この技術の概観からdockerを使用してローカルで試す具体的な方法まで掲載しているのでよかったら読んでってください。