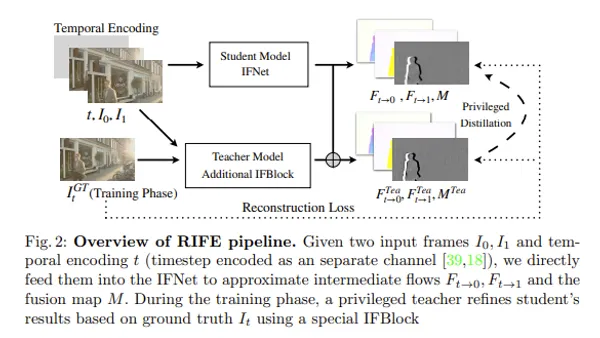
Stream Diffusionはリアルタイムで高品質な画像生成を可能にする技術です。RTX 4090で最大91.07fpsという驚異的な速度を達成しており、これは従来の方法に比べて約59.56倍のパフォーマンス向上です。
この記事ではStream Diffusionがどのようにリアルタイムの画像生成を可能にしているのかを簡単に説明します。
※概要を把握するためのノートであり、数式的な部分は扱わないので、あしからずご理解よろしくお願いします。
Stream Diffusionについて

We introduce StreamDiffusion, a real-time diffusion pipeline designed for interactive image generation. Existing diffusion models are adept at creating images from text or image prompts, yet they often fall short in real-time interaction. This limitation becomes particularly evident in scenarios involving continuous input, such as Metaverse, live video streaming, and broadcasting, where high throughput is imperative. To address this, we present a novel approach that transforms the original sequential denoising into the batching denoising process. Stream Batch eliminates the conventional wait-and-interact approach and enables fluid and high throughput streams. To handle the frequency disparity between data input and model throughput, we design a novel input-output queue for parallelizing the streaming process. Moreover, the existing diffusion pipeline uses classifier-free guidance(CFG), which requires additional U-Net computation. To mitigate the redundant computations, we propose a novel residual classifier-free guidance (RCFG) algorithm that reduces the number of negative conditional denoising steps to only one or even zero. Besides, we introduce a stochastic similarity filter(SSF) to optimize power consumption. Our Stream Batch achieves around 1.5x speedup compared to the sequential denoising method at different denoising levels. The proposed RCFG leads to speeds up to 2.05x higher than the conventional CFG. Combining the proposed strategies and existing mature acceleration tools makes the image-to-image generation achieve up-to 91.07fps on one RTX4090, improving the throughputs of AutoPipline developed by Diffusers over 59.56x. Furthermore, our proposed StreamDiffusion also significantly reduces the energy consumption by 2.39x on one RTX3060 and 1.99x on one RTX4090, respectively.

StreamDiffusionは、リアルタイムな画像生成を実現する新しいパイプラインです。従来の逐次的なノイズ除去をバッチ処理に変えているのが一番の特徴であり、Stream Diffusionの名前にもつながってると思われます。最終結果としてはRTX 4090で最大91.07fpsを達成とのことなので、従来の画像生成モデルと比べてかなり高速です。(従来の方法に比べて59.56倍のスループット改善とのこと)
Stream Diffusionの主な特徴は以下です。
- Stream Batch
- 従来の逐次的なデノイズ処理をバッチ処理に変換。高速にストリーム処理が可能。
- Residual Classifier-Free Guidance (RCFG)
- ネガティブ条件のデノイズ計算を1回または0回に削減することで、計算コストを大幅に削減。
- Input-Output Queue
- 画像生成モデルの入力と出力を保持しておくためのキュー。前処理と後処理が別スレッドで並行処理可能に。
- 確率的類似性フィルタリング
- 連続入力の類似性を評価し、GPUの無駄な使用を防ぐ。
- Pre-computation Procedure
- 事前に計算できる部分を計算しておく。
- Tiny AutoEncoder
- VAEを画像用に最適化したものに置き換える。
- Model Acceleration
- TensorRTを用いる
Stream Batch
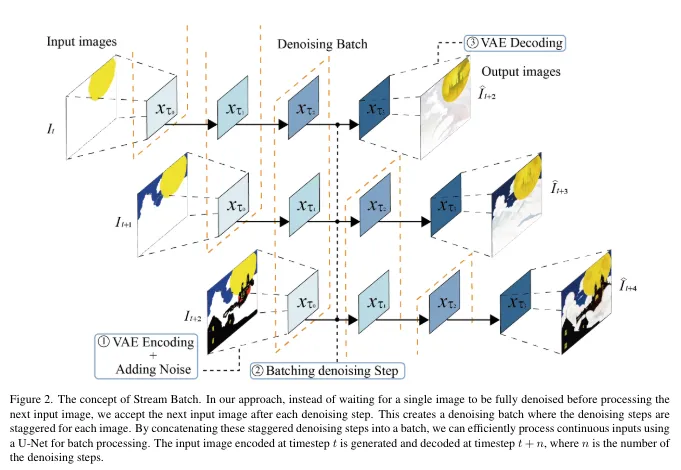
Stream Batch戦略は、逐次的なデノイズ処理をバッチ処理に変換する手法です。これにより、処理の並列化が可能となり、待機時間を削減しつつ高スループットなストリーム処理が実現されます。
従来のモデルでは、各ステップが順番に実行されるため、長い待機時間がありました。Stream Batch戦略では、複数画像のデノイズステップを一括でバッチ処理し、並列化を行います。一括で処理することで、待機時間を最小限に抑え、高速な処理が可能になります。さらに並列化により、GPUの計算資源が効率的に使用でき、これも高速化に寄与します。
以下が論文から引用してきたStream Batchのパイプラインです。オレンジの点線がおそらく同時に処理する塊を示しています。
Residual Classifier-Free Guidance (RCFG)
RCFGはポジティブプロンプトとネガティブプロンプトを用いたデノイズ処理を最適化することで、計算コストを削減しながら精度の向上を目指す手法です。具体的には次のようなことを行います。
- ポジティブプロンプトの強化
- RCFGは、従来のクラスフィアフリーガイダンス(CFG)と同様に、ポジティブプロンプトの効果を強化します。
- 仮想残差ノイズ(Virtual Residual Noise)を使用することで、ポジティブプロンプトの条件付け効果を強化し、追加のU-Net計算を削減します。
- ネガティブプロンプトの計算削減
- RCFGは初回のデノイズステップのみでネガティブプロンプトの残差ノイズを計算し、その後のステップでは仮想的に推定された残差ノイズ(Virtual Residual Noise)を使用します。
- これにより、計算コストを削減しつつ、ネガティブプロンプトの条件付け効果を維持します。
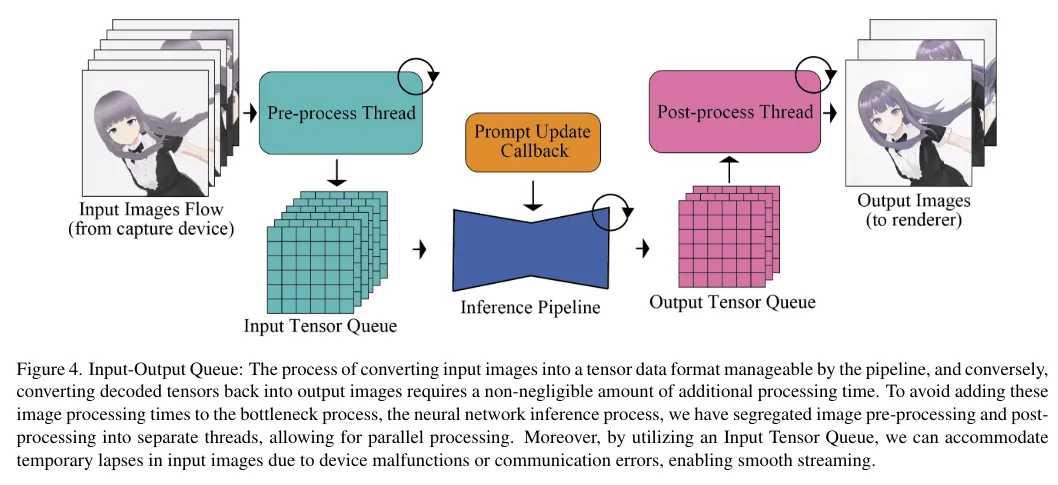
Input-Output Queue
Input-Output Queueは名前の通り、画像生成モデルの入力と出力を保持しておくためのキューです。キューを用意しておくことで画像の前処理および後処理を別スレッドで並行処理させることが可能になり、全体的なスループットを向上させることができます。通常前処理と後処理は逐次処理で行われるため、画像生成速度が遅い原因の一つになっていましたが、キューによりこのボトルネックが解消されました。
具体的には以下のキューが使用されています。
- Input Tensor Queue
- 入力データをバッチ単位で処理するためのキューです。各入力データはキューに順番に追加され、一定数(バッチサイズ)に達すると一括処理が開始されます。
- Output Tensor Queue
- モデルからの出力データを持っておくためのキューです。出力キュー内のテンソルは順番に取り出され、後処理が行われます。
以下が論文から持ってきたInput-Output Queueの構成です。
確率的類似性フィルター (Stochastic Similarity Filter, SSF)
確率的類似性フィルター (Stochastic Similarity Filter, SSF) は、拡散モデルにおいて不要な計算負荷を削減し、GPUリソースの効率的な使用を実現するための手法です。特に、入力画像が連続している場合や変化が少ない場合に、類似度の高い画像に対する計算をスキップすることで、計算資源を節約します。
実際の処理としては、画像生成処理に入る前に類似性(スキップする確率)が評価され、この確率に基づいて、VAEエンコード、U-Net、VAEデコードの処理をスキップするかどうかを決定します。スキップする場合、現在の入力画像の処理をスキップし、前の参照フレームをそのまま使用します。スキップしない場合、通常通り現在の入力画像を処理し、その結果を次の参照フレームとして保存します。
Pre-computation Procedure
前計算手順は、拡散モデルのパフォーマンスを最適化するために、事前に計算できる部分をあらかじめ計算しておく手法です。これにより、リアルタイムの処理速度が向上し、計算リソースの効率的な使用が可能になります。
具体的には下のようなことを行います。
- embeddingのキャッシュ
- embeddingを事前に計算し、キャッシュに保存します。このキャッシュを使用することで、各フレームごとにembeddingを再計算する必要がなくなります。
- ガウスノイズのキャッシュ
- 各デノイズステップで使用されるガウスノイズを事前にサンプリングし、キャッシュに保存します。
これにより、各タイムステップで異なるノイズを持たせつつ、各フレーム間で一貫したノイズを使用することができます。
- 各デノイズステップで使用されるガウスノイズを事前にサンプリングし、キャッシュに保存します。
- ノイズ強度係数のキャッシュ
- デノイズステップごとのノイズ強度係数、およびを事前に計算し、キャッシュに保存します。これにより、各フレームごとにこれらの値を再計算する必要がなくなり、計算効率が向上します。
Tiny AutoEncoder
小型オートエンコーダ (Tiny AutoEncoder) は、拡散モデルにおいて高効率な画像エンコードおよびデコードを実現するために設計された軽量なオートエンコーダです。これにより、通常のオートエンコーダに比べて計算負荷を大幅に削減しながら、高速な画像生成が可能になります。
VAEを画像の圧縮に効率化された(層の浅い)モデルに変更することで、画像データを効果的に低次元(潜在空間)に圧縮しまできるようにしました。
Model Acceleration
TensorRTでU-NETとVAEを構築することで高速化。
※TensorRTとはNVIDIAが提供しているツールキットで、ニューラルネットワークモデルを最適化してくれるやつです。(具体的には知らない)
最終的なアーキテクチャ
ここまでで説明したすべてを含めたアーキテクチャが以下の画像です。

最後に
読んでみた感じですが新しいモデルの論文というより、画像生成モデルの推論を高速化するテクニック集って感じがしますね。RTX4090で最大91.07fpsてのは驚異的で、リアルタイムでの画像生成が現実のものとなりつつあるというか、ほぼもう実現してる感じがします。あとは必要VRAMとかのスペックも落ちてくれたら完璧ですね。
将来的には、さらなるチューニングと最適化が進むことで、スマートフォンなどのモバイルデバイスでもフル機能の画像生成モデルが利用可能になることを期待しています。写真編集アプリやインタラクティブアートなど色々応用先は考えられますが、画像生成の技術がどのように進化し、どのように私たちの日常に溶け込んでいくのか、今後が楽しみです。
Stable Diffusion周りで読んだ論文は以下の記事でまとめているので、興味ある方はぜひご活用ください。

Stable Diffusion関連の論文解説記事のリンク集。画像生成・動画生成の基礎モデルから応用技術まで論文ベースで解説。