AIで動画生成する際に大抵ネックとなるのが、モデルサイズと生成時間だと思います。FramePackは動画生成の軽量化を狙った手法で、30fpsの動画をVRAMが6GBのPCでも生成できる点が一つの売りらしいです。
論文をちょろっと見た感じだと、情報として入力している過去フレームを重要度によって圧縮する(古いものをほぼ無視する)ことで過去フレーム分のメモリサイズを小さくするという手法でしょうか。つまりtransformerに入力するcontextのサイズが一定サイズ以下に抑えられるため、VRAMが最大6GB程度で済むということのような気がします。

We present a neural network structure, FramePack, to train next-frame (or next-frame-section) prediction models for video generation. FramePack compresses input frame contexts with frame-wise importance so that more frames can be encoded within a fixed context length, with more important frames having longer contexts. The frame importance can be measured using time proximity, feature similarity, or hybrid metrics. The packing method allows for inference with thousands of frames and training with relatively large batch sizes. We also present drift prevention methods to address observation bias (error accumulation), including early-established endpoints, adjusted sampling orders, and discrete history representation. Ablation studies validate the effectiveness of the anti-drifting methods in both single-directional video streaming and bi-directional video generation. Finally, we show that existing video diffusion models can be finetuned with FramePack, and analyze the differences between different packing schedules.

この記事では論文の公式デモを試してみます。実行手順も載せておくので、試してみたい方はインストラクションに沿って実行してみてください。
必要環境
- RTX 30XX以降のNVIDIA GPU(fp16, bf16がサポートされている必要がある)
- 2000番台より前は動作確認してないとのこと
- Linux or Windows
- 少なくとも6GBのVRAM
実行環境
- CPU: Intel Core i5-12400
- GPU: RTX3050(VRAM: 8GB)
- RAM: 16GB
- OS: Windows11(WSL2: Ubuntu 24.04)
実行方法(Linux)
基本的には下記リポジトリにある内容をかみ砕いてるだけなので、英語ぱっと読める方はリポジトリ側見た方が間違いがなくて良いかもしれません。
Lets make video diffusion practical! Contribute to lllyasviel/FramePack development by creating an account on GitHub.

Cudaの導入
自分の場合は導入済だったので申し訳ないですがここでは触れません(正直どうやって導入したか覚えてない)。以下のコマンドで確認できるため、もしコマンドがありません的なメッセージが出たら、調べてインストールしてください
nvidia-smi # GPUが認識されているかの確認nvcc -V # cudaのバージョン確認リポジトリをclone
# 任意のworkspaceを作成し移動mkdir ~/workspacecd ~/workspace# 現在のリポジトリにcloneするgit clone https://github.com/lllyasviel/FramePack.git .依存関係のinstall
任意の方法でpython3.10と依存ライブラリをインストールします。自分はpyenvを使用しましたが、aptとかでも可能です。
# pythonのインストールpyenv install 3.10pyenv local 3.10
# 仮想環境を作成(globalで良ければ作らなくてもよい)python -m venv venvsource venv/bin/activate
# pythonパッケージのインストールpip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu126pip install -r requirements.txtデモの実行
モデルのダウンロードなどが走るためだいぶ時間がかかりますが、気長に待ちましょう。
python demo_gradio.pyデモアプリへのアクセス
デモの起動が完了すると以下のように表示されるので、ブラウザでアクセスします
* Running on local URL: http://0.0.0.0:7860表示された!!!
生成結果
設定は全部デフォルトのままで生成してます。1秒分のフレームを生成するのに大体10分ほど。
生成結果1
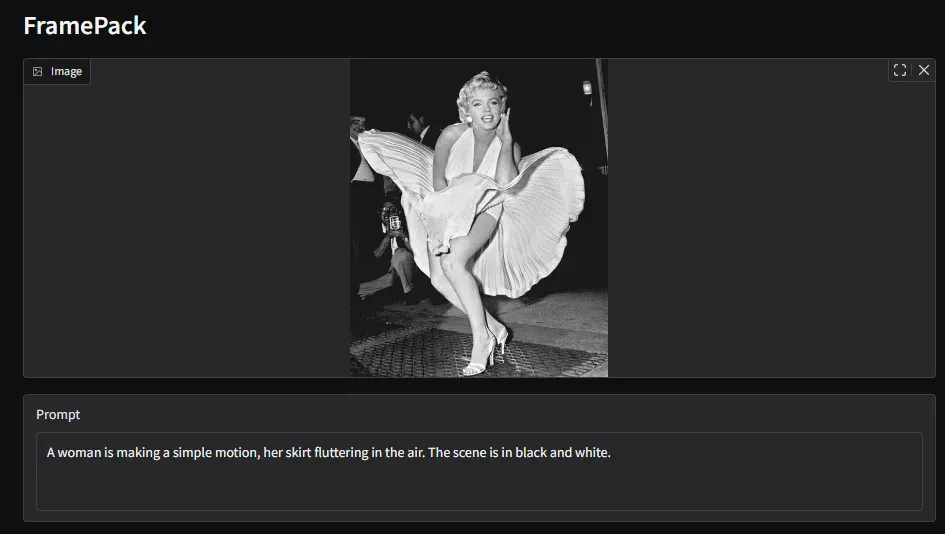
あー、多分最初のポーズが変則的過ぎましたね…あとプリーツも表現しきれてない。
生成結果2
悲しいので別の画像でリベンジ。肖像権とか調べるの面倒になったので以前生成した画像から。
今度は動きが小さめ。
最後に
時間はかかりつつも、VRAM8GBでも普通に生成できました。仕組み的に生成フレーム増やしても生成時間が線形的に増えてくだけだと思うので、低スペックで長めの動画生成したいときとか、意外に有用だったりするんじゃないかなと思います。
まあ運悪いと崩れるのは生成AIの宿命ですね…。仕組み上減ることはあってもなくなることはなさそうです。
導入で詰まったとか、何か質問などあれば気軽にコメントください。