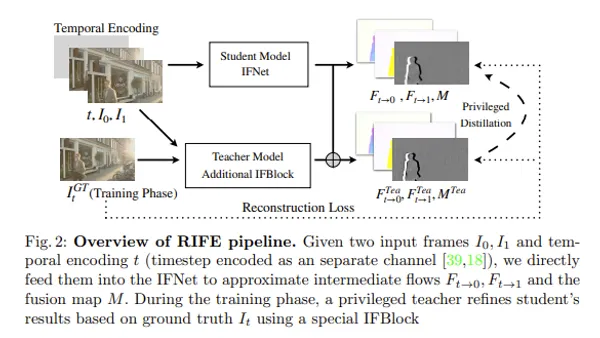
This time I will introduce Textual Inversion (embedding). Textual Inversion is a technique to control output of Stable Diffusion from aspect of language, and by using it, it becomes possible to bring output closer to favorite art style or composition. In short, it means it becomes easier to output picture you want to output.
Heating only this, some might wonder what is different from LoRA, and exactly as that, what Textual Inversion and LoRA are trying to do is almost same. What differs is from which angle they try to control, LoRA tries to control output from aspect of architecture, Textual Inversion from aspect of input prompt (more specifically Text Encoder).
In this article I will check about mechanism of Textual Inversion.
What is embedding
Before entering explanation of Textual Inversion, I insert explanation about embedding which becomes important in this paper.
Overview of embedding
Embedding is what converted word (prompt) to mathematical vector, with this base model becomes able to understand meaning of prompt. For example, by converting word “cat” to list of numbers computer can understand, it becomes possible to compare numerically whether it is similar compared to other words.
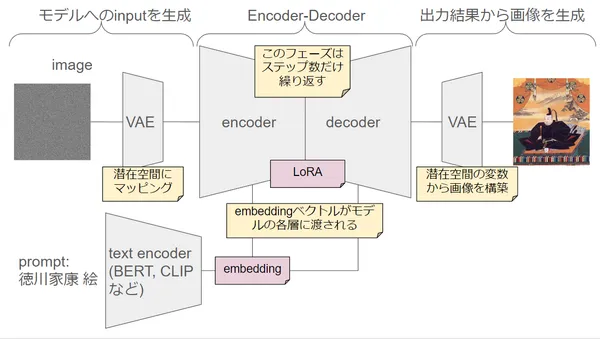
In Stable Diffusion model, vector output from Text Encoder corresponds to embedding as in figure below.
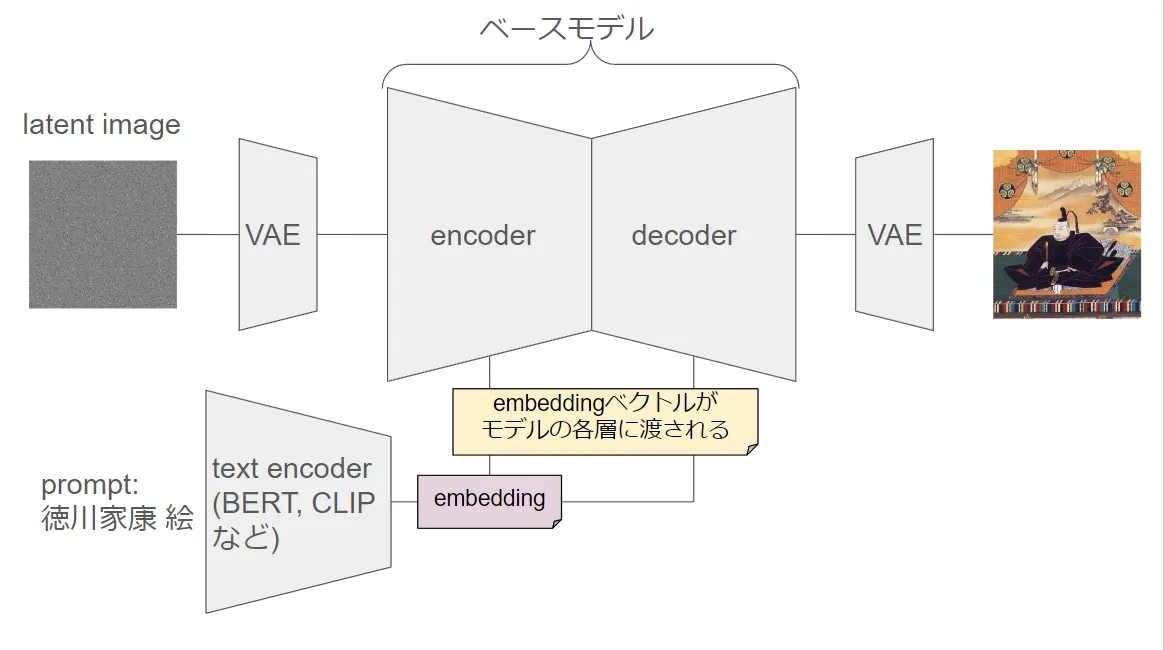
Processing of embedding
In Stable Diffusion model, embedding is usually generated and processed through following process.
- Input of Prompt:
- First, user inputs prompt (instruction) like “Draw picture of cat”.
- Processing of Text Encoder:
- Prompt is sent to Text Encoder (e.g. BERT or CLIP). Text Encoder converts words of prompt to list of mathematical numbers, i.e. “Language Vector (embedding)”. Language Vector is thing to make computer easy to understand meaning of words.
- Generation of Language Vector:
- Text Encoder uses learned weights (information model learned with many data) to generate embedding reflecting content of prompt. For example if word “cat” is included, number list having features related to that word is generated.
- Input to Base Model:
- Generated embedding is input to base model like Stable Diffusion. This base model interprets embedding and generates image based on instruction.
About Textual Inversion

Text-to-image models offer unprecedented freedom to guide creation through natural language. Yet, it is unclear how such freedom can be exercised to generate images of specific unique concepts, modify their appearance, or compose them in new roles and novel scenes. In other words, we ask: how can we use language-guided models to turn our cat into a painting, or imagine a new product based on our favorite toy? Here we present a simple approach that allows such creative freedom. Using only 3-5 images of a user-provided concept, like an object or a style, we learn to represent it through new "words" in the embedding space of a frozen text-to-image model. These "words" can be composed into natural language sentences, guiding personalized creation in an intuitive way. Notably, we find evidence that a single word embedding is sufficient for capturing unique and varied concepts. We compare our approach to a wide range of baselines, and demonstrate that it can more faithfully portray the concepts across a range of applications and tasks. Our code, data and new words will be available at: https://textual-inversion.github.io

Overview of Textual Inversion
Textual Inversion is a technique to change direction of generated embedding by training Text Encoder. (Please refer to image below for position of Text Encoder.) In other words, learn new concept or word, generate new language vector matching it, and make it form interpretable by base model. Thus, model becomes able to generate images using new word or concept.

Learning Method of Textual Inversion
- Data Collection:
- Collect 3-5 images having specific concept and corresponding text description. For example collect “Portrait of Ieyasu Tokugawa” and its description text.
- Embedding Generation:
- Add new token to existing Text Encoder (e.g. CLIP).
- Using pair of image and text, learn embedding of new token.
- Embedding Optimization:
- Optimize (Learn) generated embedding to match existing embedding space of model.
- (At this time weights of original model remain frozen, learn only embedding)
Evaluation Result
You can see output changes just by changing image used for learning.

Conclusion
Textual Inversion is very useful technology in utilizing Stable Diffusion. By understanding this technique and actually applying, it becomes possible to generate images exactly as you envision. By grasping difference with LoRA and choosing appropriate method, you can obtain result with even higher precision. I am happy if understanding about basic mechanism of Textual Inversion deepened through this article.
Method to try Textual Inversion is explained in following article. Please read here if you want to try.

>-
Since papers read around Stable Diffusion are summarized in following article, please utilize if interested.
Stable Diffusion関連の論文解説記事のリンク集。画像生成・動画生成の基礎モデルから応用技術まで論文ベースで解説。