HomelabでいつのまにかPodが死んでる時ありますよね。そのままにしておくのも寝覚めが悪いので、kubectl logs を叩いて原因を確認して、values.yaml を直して push して ArgoCD sync を待って……というフローをやるのですが、これが地味に面倒です。
そこで、Claude Code のスキル機能を使ってこの一連の作業を自動化することにしました。/k8s-ops というコマンドを呼ぶだけで、クラスターの診断・原因特定・修復提案・実行まで Claude が自律的にやってくれます。さらに /inference-tune というスキルで LLM 推論の速度チューニングも自動化しました。最終的に Hermes(AI エージェント)の実使用 TPS が 21 t/s から 32+ t/s になった話をします。
Claude Code スキルとは
Claude Code にはスキル(slash command)という仕組みがあります。プロジェクトの .claude/skills/<name>/SKILL.md に置いておくと、そのプロジェクト内で /<name> として呼び出せるようになります(~/.claude/skills/ に置けばどのプロジェクトでも使えるグローバルスキルになります)。
重要なのは frontmatter の allowed-tools フィールドで、スキルが使える CLI ツールを明示的に制限できます。
---name: k8s-opsallowed-tools: Bash(~/bin/kubectl *) Bash(kubectl *) Bash(bash /home/yamato/otama-homelab/.claude/skills/k8s-ops/scripts/*) Read---k8s-ops スキルでは ~/bin/kubectl(固定バイナリ v1.36.1)と、事前に書いた診断・操作スクリプトだけを許可しています。ファイル書き込みや任意のシェルコマンドは許可していないので、Claude が予想外の操作をする心配がありません。
k8s-ops スキルの構成
ファイル構成はこうなっています。
.claude/skills/k8s-ops/├── SKILL.md — スキル定義・クラスター情報・操作フロー└── scripts/ ├── k8s-diagnose.sh — 全 namespace の健全性チェック ├── k8s-ops.sh — Pod 操作・ArgoCD 操作の安全ラッパー └── k8s-node-resources.sh — ノード・VRAM・推論速度のサマリー認証情報などは固定パスに置き、コマンド実行時に勝手に参照されるようにしてあります。
| 項目 | 値 |
|---|---|
| KUBECONFIG | ~/.kube/config |
| api-server(master ノードに向ける) | 192.168.100.151:6443 |
| kubectl | ~/bin/kubectl (v1.36.1) |
安全ハーネスの設計
Claude に操作させる以上、誤操作のリスク管理が必要です。SKILL.md にリスクレベルを明記して、Claude が操作の前に必ず確認フローを踏むよう設計しました。
| レベル | マーク | 操作例 | 実行方法 |
|---|---|---|---|
| SAFE | 🟢 | get / describe / logs / top / diagnose | 自動実行(確認不要) |
| MODERATE | 🟡 | Pod 再起動 / rollout restart / scale | 提案表示 → 1 回確認 |
| HIGH | 🔴 | Pod 強制削除 / リソース削除 / cordon | 内容明示 → 確認必須 |
| CRITICAL | ⛔ | node drain / namespace 削除 | 二重確認 + 影響説明 |
クラスター構成
homelabは現状3ノード構成で動いています。
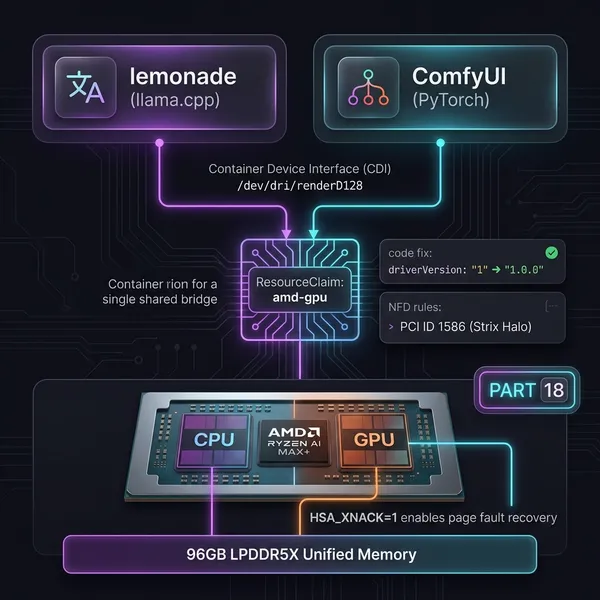
k3s-01 control-plane 192.168.100.151k3s-02 worker 192.168.100.152k3s-03-ai worker/AI 192.168.100.104 (AMD Radeon GPU, VRAM 96 GB)k3s-03-ai は Strix Halo(Ryzen AI MAX+)搭載です。128 GB の物理メモリのうち 96 GB を VRAM として GPU に割り当てており、残り 32 GB が CPU RAM として使われています。以前の記事で MES ファームウェアのバグにハマって 3 日間を溶かしたノードがこれです。
Namespace の全体像は前のパートで一通り書いたので、ここでは今回の話に関わる 2 つだけ挙げておきます。
| Namespace | 役割 |
|---|---|
| inference | AI 推論(lemonade / litellm / comfyui / qdrant) |
| argocd | GitOps(ArgoCD) |
実際の使い方
診断
/k8s-ops クラスターの状態を確認して と書くと、Claude が k8s-diagnose.sh を実行して結果をサマリーしてくれます。異常な Pod があれば優先度順に整理して報告が来ます。
修復
CrashLoopBackOff があれば、Claude がログを読んで原因を特定します。たとえば依存サービスへの接続失敗なら ConfigMap の設定ミスを指摘して、修正内容を提示したうえで確認を求めてきます。承認すれば実行されます。
ログを手動で grep して原因を追いかける必要がなくなりました。Pod が落ちているのに気づいたら /k8s-ops を呼んで承認を押すだけ、という状態になっています。
inference-tune スキル
k8s-ops でクラスターの診断・修復が一通り自動化できたので、同じ要領でもう一つスキルを作りました。推論速度のチューニング専用の /inference-tune です。
.claude/skills/inference-tune/├── SKILL.md — ワークフロー・パラメーターリファレンス├── KNOWLEDGE.md — 調査済み知見・ベースライン TPS├── TASKS.md — タスク状況・進捗トラッキング└── scripts/ └── check-perf.sh — 推論速度・VRAM・MTP ステータス確認チューニングのワークフロー
/inference-tune を呼ぶと、Claude が以下の手順を踏みます。
TASKS.mdを読んで前回の続きから作業を再開するKNOWLEDGE.mdを読んで、調査済みの問題・既知の制限を確認するcheck-perf.shで現状の TPS・VRAM・MTP 有効状態を診断するvalues.yamlの変更案を提示する- git commit → push → ArgoCD refresh/sync を実行する
- 再診断して効果を確認する
- 結果を
KNOWLEDGE.mdに書き戻す
KNOWLEDGE.md を挟んでいるのは「同じ調査を二度しない」ためです。一度試して効果のなかったパラメーターや、lemonade の既知の制限を記録しておきます。次のセッションでも Claude が最初に KNOWLEDGE.md を読んでから作業を始めるので、前回の知見が引き継がれます。
ArgoCD との兼ね合い
このクラスターのほぼ全 Deployment は ArgoCD 管理下にあります。kubectl patch で直接変更しても、次の ArgoCD sync で元の値に上書きされます。
チューニングパラメーターは必ず values.yaml を編集して git push → ArgoCD sync のルートを通す必要があります。一時的なデバッグのための確認には直接 patch を使うことはありますが、恒久的な変更はすべて Git 経由にしています。
Claude が自律的にやったこと
/inference-tune を呼ぶたびに Claude が KNOWLEDGE.md を読んで診断し、values.yaml を変更して ArgoCD でデプロイして、結果を KNOWLEDGE.md に書き戻す、というループを回します。自分はそのつど承認ボタンを押すだけです。
実際に Claude が見つけて直したことを並べてみます。
まず分かったのが、Hermes のベースコンテキストが 17K tokens もあったことです。ツール定義とシステムプロンプトが毎回リクエストに乗るので、ショートコンテキストのベンチマークでは 50+ t/s 出ていても、実使用の TPS は最初から〜21 t/s しか出ていませんでした。ベンチと体感が噛み合わない原因がこれです。
次に、MTP の有効化方法が間違っていました。llamacppRocmArgs に --spec-type draft-mtp と書いても lemonade には無視されます。正しくは lemonade pull 時に "mtp" ラベルを付ける方式で、inference/values.yaml の labels: フィールドで設定します。これでショートコンテキストのベンチマーク TPS は 47〜48 → 57〜58 t/s と約 20% 改善しましたが、17K ベースが積まれた実使用では効果は限定的でした。
ツールの無効化も、設定値ミスでそもそも効いていませんでした。disabledToolsets に video_generate と書いていたのですが、正しくは video_gen。ずっと有効化されたままだったわけです。同じようなミスを直しつつ、不要な 7 toolset と 24 スキルも削除して、合わせて約 2,600 tokens 削減しました。それでも根本的な 17K の壁は超えられない。
一番厄介だったのが圧縮です。Hermes には会話が長くなると古いメッセージを圧縮する機能があるのですが、これがまったく動いていませんでした。最初は compressionThreshold: 0.25 で、ベースの 17K が既に閾値を超えていて発火しない。0.28 に上げたら今度は noop バグを踏んで、コンテキストが 17K → 51K まで膨らみ TPS が 11 t/s まで落ちる。最終的にパラメーターを調整してようやく正常に発火するようになり、実使用 TPS が 32〜35 t/s まで改善しました。ただしこの値はベースのサイズを前提にしているので、ツール構成が変わると条件が崩れます。その後もコンテキスト上限の拡張などで何度か再調整するハメになりました。
API タイムアウトもありました。Pod 再起動直後の cold start prefill に約 2 分かかるのに、タイムアウトがデフォルトの 120 秒のまま。config.yaml の設定が実際の httpx クライアントに繋がっていないことを突き止めて、deployment の環境変数を追加して解消しました。
最後は VRAM 不足で、モデルが追い出されていた件です。35B(52 GB)と 26B(27 GB)を同時に乗せると 64 GB VRAM を超えてしまい、リクエストのたびにモデルのロード待ちが発生していました。これは BIOS で VRAM を 96 GB に拡張して解消。今は 35B・26B・4B・Embedding の 4 モデルが常時ロードされています。
これら(記載していない細かい修正を含め)をすべて /inference-tune を呼びながらセッションをまたいで Claude がこなしました。KNOWLEDGE.md があるので、前のセッションで「このパラメーターは効かない」と記録されていれば次のセッションではそこをスキップして先に進んでくれます。自分で調査メモを取り続けなくていい、というのが体感として一番楽になった部分です。
まとめ
k8s-ops スキルを使うようになってから、Pod の異常対応がだいぶ楽になりました。Claude が診断から修復提案までほぼ自律的にやってくれて、自分は承認するだけでいい状態です。
inference-tune スキルは最初「TPS を上げたい」という目的で作りましたが、結果として圧縮バグ・タイムアウト・VRAM 問題まで芋づる式に Claude が発見・修正してくれました。自分がやったことは「承認」と「BIOS の変更」くらいです。
SKILL.md と KNOWLEDGE.md を Markdown で書いておくだけで、Claude にとっての作業マニュアルと調査ノートになります。使うたびに育っていくのが気に入っています。
同じような homelab 環境で Claude Code を使っている方の参考になれば幸いです。