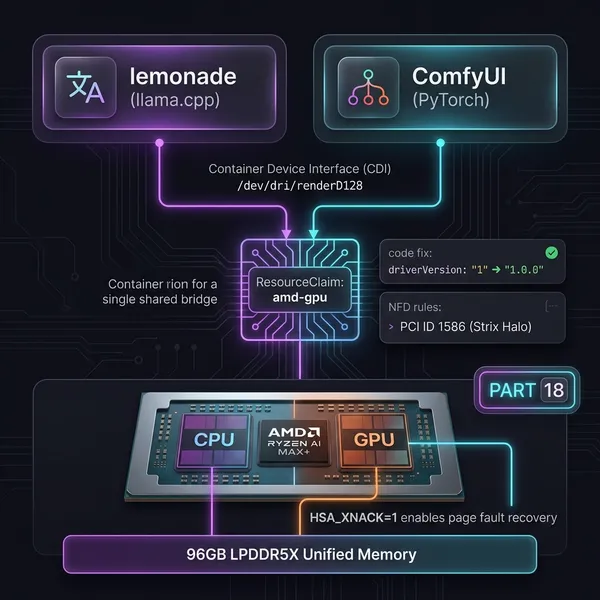
前回の記事でMESファームウェアのバグを倒してlemonadeが動くようになりました。ところが、しばらく使っていると別の問題が出てきました。今回はその話です。
何が起きたか
lemonadeが推論中にクラッシュしました。モデルのロード中やOOM(Out of Memory)でプロセスが死ぬのは推論サーバーあるあるなのですが、問題はその後でした。
Podが再起動しても、GPUが使えない。VM内の dmesg を見ると、以下のエラーを吐いて止まっています。
[ 40.4] amdgpu: PSP tmr init failed!VM を再起動してもダメ。ホストを再起動してもダメ。電源を一度落とすコールドブート(完全放電までは試していませんが)をしてもダメ。
これには少し驚きました。ソフトウェアリセットはもちろん、OSレベルで電源を落としてもGPUの汚い状態がクリアされないことがあるんですね。
なぜ回復できないのか
Strix HaloはAPUなので、GPU側のPSP(Platform Security Processor)がCPU側のASP(AMD Security Processor / CCP)と密結合しています。lemonadeがGPUをクリーンにリリースせず終了すると、PSPがTMR(Trusted Memory Region)を汚い状態のまま残してしまう、ということのようです。
次回起動時にPSPが初期化しようとするとこの汚い状態に当たり、UNKNOWN CMD(0xFFFFFFFF)(タイムアウト)で失敗します。
VFIO環境ではCPU側のASPを「VMとして」パススルーしているため、ホスト側の物理リソースに直接アクセスできません。このため、VFIO越しではPSPのリセットが正しく機能しないようです。ベアメタルでは同じクラッシュが起きてもPodを再起動するだけで回復できるので、VFIO特有の問題だと考えています。
ほぼほぼredditからの受け売りですが、ある程度説明はついているのかなと思います。
試したこと
FLR(Function Level Reset)
echo 1 > /sys/bus/pci/devices/0000:c5:00.0/reset効果なし。PSPのファームウェア状態はFLRでクリアされません。
vendor-resetモジュール
AMDのGPUリセット問題の定番解決策ですが、kernel 7.x系ではビルドが失敗します。そもそもStrix Haloには非対応でした。
どちらも解決には至らず、ここで打ち手が尽きました。
ベアメタルに切り替える
「Incus VMをやめて、直接ベアメタルにUbuntuを入れてk3sを動かせばいい」という当たり前の結論にたどり着きました。
他のノードとアーキテクチャをそろえられないのは少し惜しいですが、GPUクラッシュのたびにコンセントを抜くしかない構成では、運用として成り立ちません。
落ち着いた構成
- ベアメタルUbuntu 26.04(Incus無し)
- カーネル組み込みのamdgpu + ROCm 7.2.3
- k3sエージェントを直接インストール
- AMD GPU Operator + DRAドライバーでKubernetesからGPUを利用
lemonadeがクラッシュしてもPodが再起動すれば普通に回復するようになりました。VFIOの頃とは比べ物にならない安定性です。
まとめ
VFIOパススルーは動いているときは良いのですが、Strix HaloのようなAPUでは、GPUがdirty状態になったときにソフトウェアで回復する手段がありません。クラッシュを完全に防げない推論サーバーの用途では、VFIO構成の継続は難しいと判断しました。
ベアメタルは「当たり前の選択」に見えて最初は抵抗がありましたが、安定して動いているのが一番です。
同じ構成で詰まっている方の参考になれば幸いです。