Mac Studio M4 Max の 128GB モデルを買うつもりでいたのに、気づいたら在庫がどこにも見当たらなくなっていました。諦めて GMKtec EVO-X2 にしましたが、それでも 47 万。部品高騰、恐るべし。
(正直M4 Maxが欲しかったですが、Mac用のVirtual Kubelet実装を自作しなくてよくなったということで喜んでおきます。)
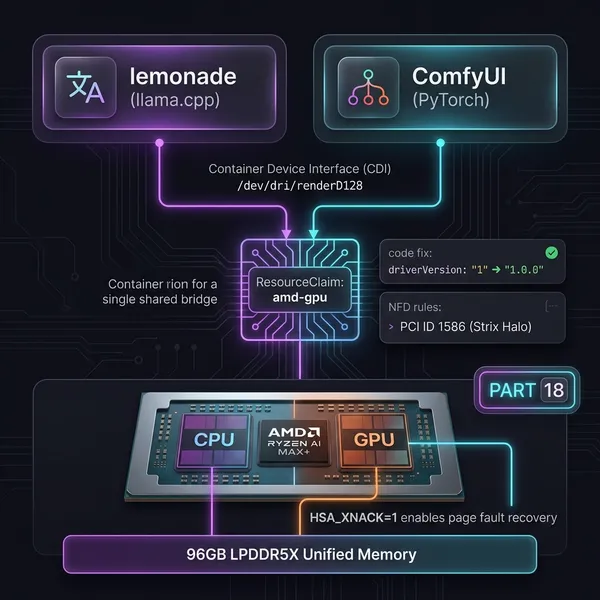
EVO-X2 は Ryzen AI MAX+ 395 を搭載した小型 PC で、LPDDR5 128GB の統合メモリを CPU と GPU が共有します。BIOS の設定で 96GB を GPU メモリとして割り当てられるので、それなりのサイズのモデルを動かせます。今回の目的は k8s クラスタに GPU 推論ノードとして参加させること。まず ComfyUI を動かすところまで確認しました。
構成

物理ホストで IOMMU を有効にして GPU を Incus VM にパススルーし、その VM の中で k3s エージェントを動かす構成です。ArgoCD GitOps でワークロードをデプロイしています。
とりあえず共通セットアップ
クラスタに参加させるまではいつも通り。過去の記事を搔い摘まんで思い出しながら、何となく進められました。
- Windows を消して Ubuntu 26.04 をインストール
- Incus をインストール
- ネットワークのブリッジを設定
- VM を作成してホストのネットワークに参加させる
この辺の詳細は過去の記事に譲ります。
GPUパススルー設定(ホスト側)
ここからが本命。パススルー周りは完全にお初なので、AIに教えてもらいながら進めました。
GRUBの修正
vfio-pci.ids= をカーネルパラメータで渡すことで、起動エントリごとに GPU の帰属先を切り替えられます。
sudo nano /etc/default/grub変更する箇所:
# 通常起動(VM GPUモード): GPU と ASP/CCP を両方渡す ← 後述GRUB_CMDLINE_LINUX_DEFAULT="quiet splash amd_iommu=on iommu=pt vfio-pci.ids=1002:1586,1022:17e0"
# GRUBメニューを表示GRUB_TIMEOUT_STYLE=menuGRUB_TIMEOUT=5sudo update-grubvfio-pci softdep 設定
ids= はカーネルパラメータで渡すため、modprobe.d には softdep のみ書きます。
sudo tee /etc/modprobe.d/vfio.conf << 'EOF'softdep amdgpu pre: vfio-pcisoftdep ccp pre: vfio-pciEOF
# modules-load.d の vfio 設定があれば削除(カーネルパラメータで制御するため不要)sudo rm -f /etc/modules-load.d/vfio.conf
sudo update-initramfs -uトラブルシューティング用 GRUBエントリの追加
GPU を VM に渡してしまうとホスト側で画面が出なくなります。設定を触りたくなったときのために、vfio-pci.ids= を渡さないエントリを追加しておくと便利です。
sudo tee /etc/grub.d/40_custom_ai_debug << 'EOF'#!/bin/shexec tail -n +3 $0menuentry "Ubuntu - GPU Troubleshooting (Display ON, VM GPU OFF)" { insmod part_gpt insmod ext2 # ※ UUID はご自身の環境のものに差し替えてください(blkid で確認できます) search --no-floppy --fs-uuid --set=root YOUR-EFI-PARTITION-UUID linux /vmlinuz-7.0.0-15-generic root=UUID=YOUR-ROOT-PARTITION-UUID ro quiet splash amd_iommu=on iommu=pt initrd /initrd.img-7.0.0-15-generic}EOFsudo chmod +x /etc/grub.d/40_custom_ai_debugsudo update-grub有効化確認(再起動後)
# IOMMU が有効か確認dmesg | grep -i iommu | head -20
# GPU の IOMMU グループを確認for d in /sys/kernel/iommu_groups/*/devices/*; do n=${d#*/iommu_groups/*}; n=${n%%/*} printf 'IOMMU Group %s ' "$n" lspci -nns "${d##*/}"done | grep -i "AMD\|Radeon\|display\|VGA"詰まりポイント — ASP/CCP も一緒にパススルーしないと GPU が起動しない
今回最大のハマりポイントがここでした。
GPU(Device ID 1002:1586)だけを VM に渡したところ、VM 内で amdgpu が以下のエラーを吐いて初期化に失敗します。
[drm] PSP tmr init failed!amdgpu 0000:01:00.0: amdgpu: Failed to load gpu_info firmwareamdgpu: probe failed with error -22原因は AMD Secure Processor(ASP / CCP、Device ID 1022:17e0)にあります。
Strix Halo の GPU は、CPU 側の AMD Secure Processor と連携して TOC ファームウェアをロードする仕組みになっています。GPU だけをパススルーすると ASP がホスト側に残ったまま vfio-pci に掴まれず、VM 内から到達できなくなります。その結果、PSP の初期化が UNKNOWN CMD(0xFFFFFFFF) で失敗するという流れです。
APU 特有の構造で、この挙動を解説している情報がほぼなく、かなり時間を使いました。同じ構成で詰まっている人がいれば、まずここを疑ってみてください。
解決策は GPU と ASP を両方パススルーすること。GRUB の vfio-pci.ids= に両方の Device ID を書き、modprobe.d の softdep も両方設定します。
GRUB_CMDLINE_LINUX_DEFAULT="... vfio-pci.ids=1002:1586,1022:17e0"softdep amdgpu pre: vfio-pcisoftdep ccp pre: vfio-pci ← これが抜けるとダメStrix Halo に限らず APU 系の VFIO パススルーでは、GPU 以外の関連デバイスも IOMMU グループを確認して一緒に渡す必要がある、ということです。
GPUパススルー設定(Incus側)
通常起動(GPU が vfio-pci に掴まれている状態)で VM を設定します。PCI アドレスはご自身の環境の lspci 出力を使ってください。
sudo incus stop k3s-03-ai --force 2>/dev/null; true
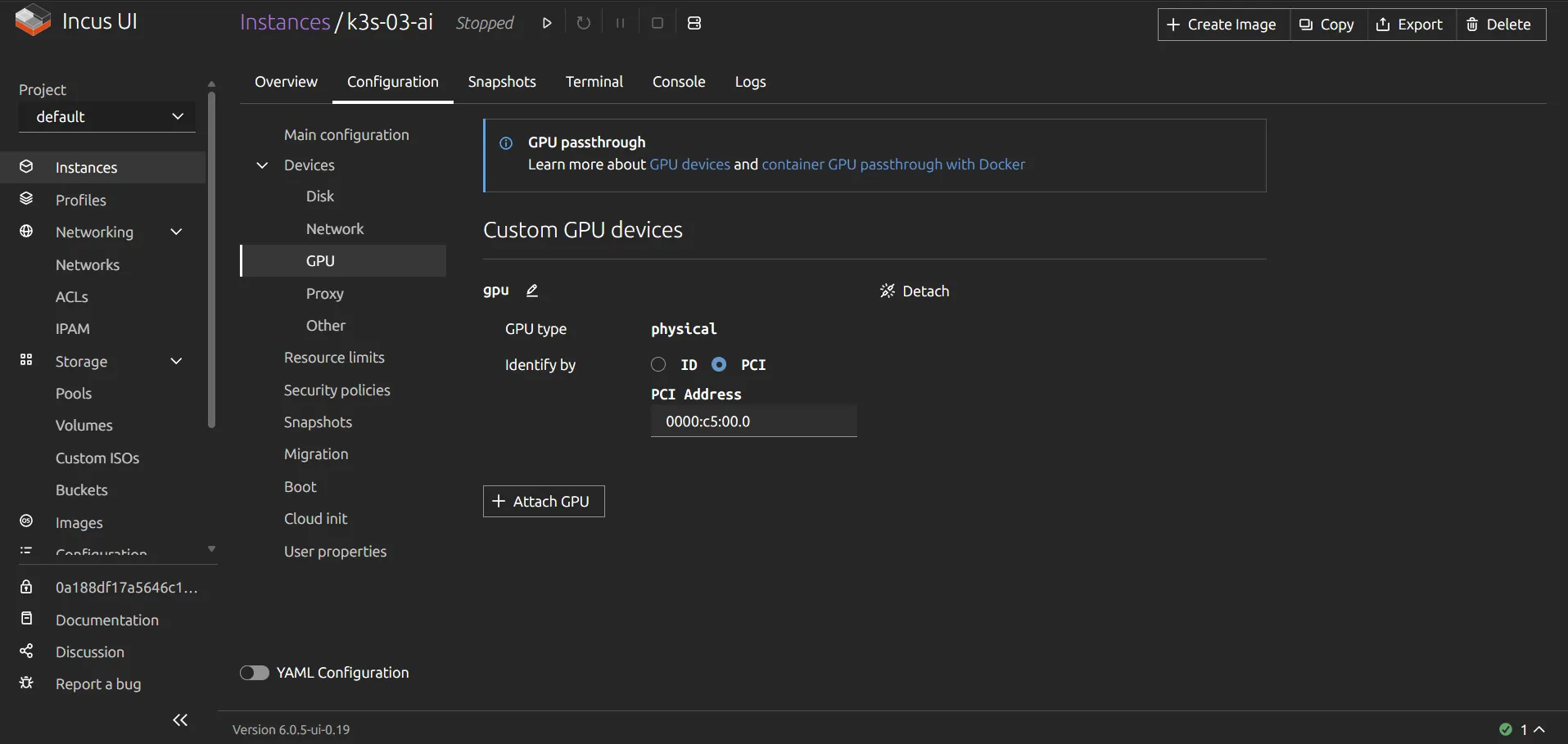
# GPU と ASP の両方を追加sudo incus config device add k3s-03-ai gpu gpu pci=<GPUのPCIアドレス>sudo incus config device add k3s-03-ai asp pci address=<ASPのPCIアドレス>
# セキュアブートを無効化(vfio-pci パススルーに必要)sudo incus config set k3s-03-ai security.secureboot=false
sudo incus start k3s-03-aiWebUI でも確認できます。ここから設定することも多分可能です。
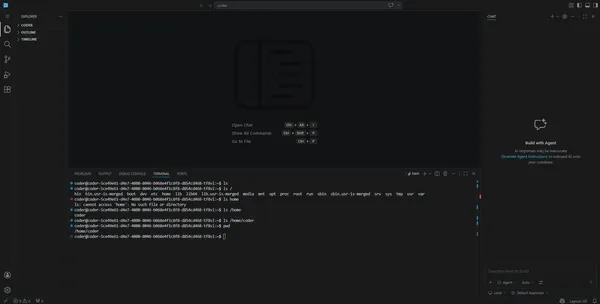
VM 内からも確認しておきます。
sudo incus exec k3s-03-ai -- ls /dev/dri/# → renderD128 などが表示されれば OKROCmのインストール
インストール先は VM 内(k3s が動くノード)です。ホストや Incus 本体には入れないように注意してください。GPU がパススルーされているので、ホスト側にドライバーは不要です。
公式ドキュメントには Ubuntu 24.04 が必要と書いてありますが、Ubuntu 26.04 に apt でそのまま入れて動くという情報は大量に出ているので、気にせず進めます。ただし一つ罠があります。

System requirements for AMD ROCm
apt install rocm を実行すると amdgpu-dkms が依存として引き込まれ、ビルドが失敗します。
error: implicit declaration of function 'zone_device_page_init'カーネル 7.x でシグネチャが変わった関数を amdgpu-dkms(6.16.x 系)が使っているためです。Ubuntu 26.04 のカーネル組み込み amdgpu は動くので DKMS 版は不要。先にホールドしてから ROCm を入れます。
sudo apt updatesudo apt install -y linux-firmware
# amdgpu-dkms はカーネル 7.x と非互換のためホールドsudo apt-mark hold amdgpu-dkms
sudo apt install rocm -y
sudo usermod -aG render,video $USER確認
nvidia-smi みたいな確認コマンドがあるので使ってみます。
rocminfo | grep -E "Name:|Marketing"Name: AMD RYZEN AI MAX+ 395 w/ Radeon 8060SMarketing Name: AMD RYZEN AI MAX+ 395 w/ Radeon 8060SVendor Name: CPUName: gfx1151Marketing Name: AMD Radeon GraphicsVendor Name: AMDrocm-smiDevice Node IDs Temp Power VRAM% GPU%0 1 0x1586, 44266 34.0°C 8.015W 0% 0%Device 0 が表示されて VRAM% と GPU% が見えれば動いています。
なお、BIOS の UMA Frame Buffer Size を設定していないと VRAM が少ないままです。Auto だと実測で約 61GB しか割り当たらなかったので、96GB に固定しておくのが確実。rocm-smi で VRAM Total: 98304 MiB と表示されれば OK です。
k8sの準備
クラスタへの参加
好きな k8s ディストリビューションを入れてクラスタに参加させれば完成です。今は k3s を使っているので k3s で進めます。
kubectl get nodes -o wideNAME STATUS ROLES AGE VERSION INTERNAL-IPk3s-01 Ready control-plane 5d18h v1.35.4+k3s1 192.168.100.151k3s-02 Ready <none> 5d18h v1.35.4+k3s1 192.168.100.152k3s-03-ai Ready <none> 4h9m v1.35.4+k3s1 192.168.100.154推論ノード用ラベルを追加
kubectl label node k3s-03-ai role=inferencekubectl label node k3s-03-ai accelerator=amd-gpuAMD GPU Device Plugin
k8s で AMD GPU をリソースとして使うには公式の device plugin が必要です。
Kubernetes (k8s) device plugin to enable registration of AMD GPU to a container cluster - ROCm/k8s-device-plugin

manifest の nodeSelector に accelerator: amd-gpu を指定して、推論ノードのみに DaemonSet として追加します。詳細な定義はドキュメントを参照してください。
適当なアプリをデプロイする
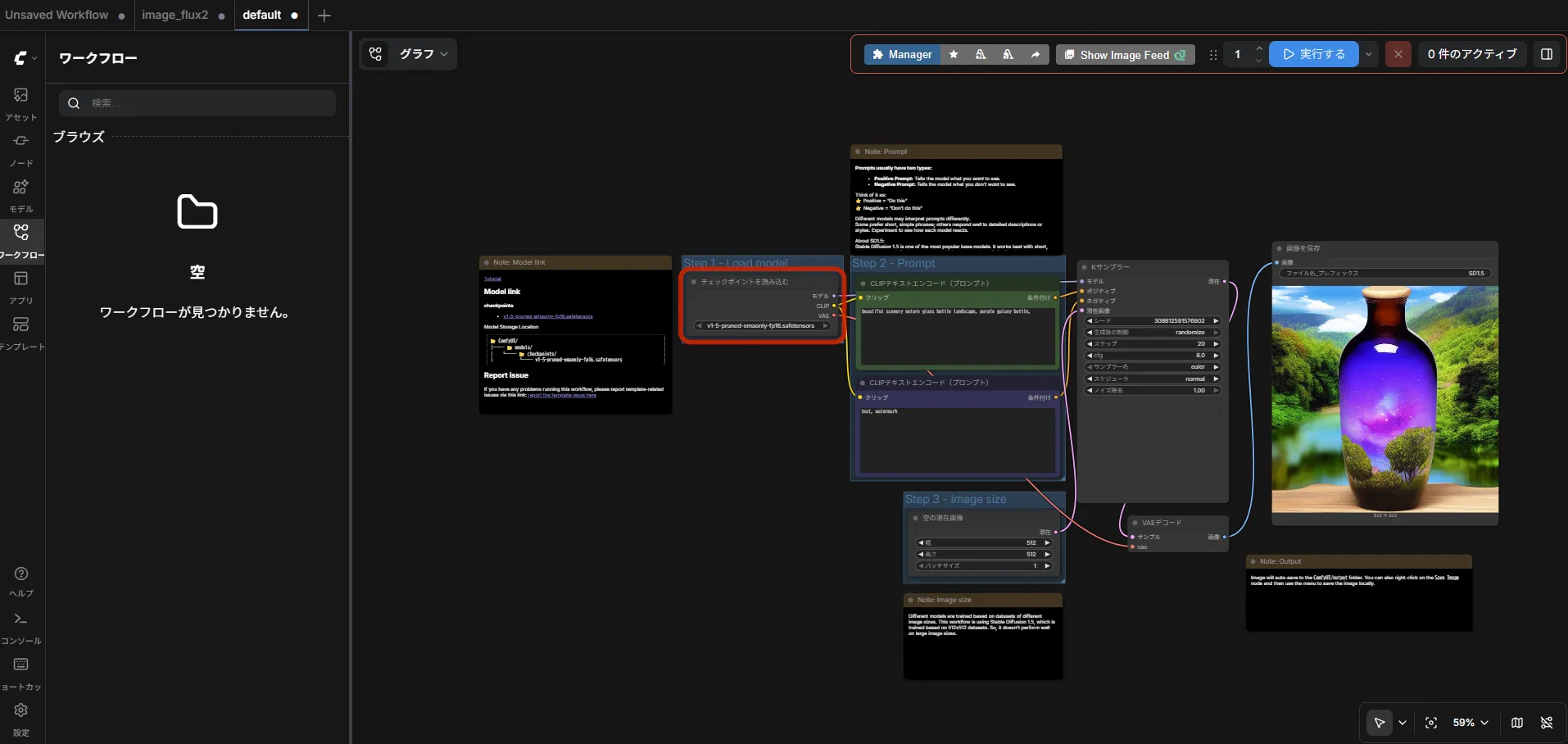
とりあえず ComfyUI で試しました。nodeSelector で accelerator: amd-gpu を指定してリソースも追加するだけです。
nodeSelector: accelerator: amd-gpuresources: limits: amd.com/gpu: "1"加えて、環境変数として HSA_OVERRIDE_GFX_VERSION=11.5.1 を渡すことで gfx1151(Strix Halo)が ROCm に認識されます。これを渡さないと GPU が見えないので注意です。
画像生成もちゃんと動いていました。
終わりに
とりあえず使い方は分かってきたので、また今度 LLM なども立ててみます。
ローカル LLM でコーディングエージェントを回し放題にするとか、スピーカーとマイクを繋いで会話エージェントを作るとか、動画生成を試すとか。sunshine を使ってゲームのストリーミングもしてみたい。やりたいことはいくらでもあるのに、もう週末が終わってしまいました。
同じ構成で詰まっている方の参考になれば幸いです。
参考
System requirements for AMD ROCm
Kubernetes (k8s) device plugin to enable registration of AMD GPU to a container cluster - ROCm/k8s-device-plugin