LiteLLM Proxy を使って、ローカルで動いている LLM と ChatGPT サブスクリプション経由のモデルを一本のエンドポイントにまとめた話をします。
面白いのは ChatGPT の接続方法で、API キーを使わずに ChatGPT サブスクリプションを API の代わりに使えます。gpt-5.5 も gpt-5.4-mini も、サブスクで叩けます。API 課金と比べてコスパがいい使い方です。
ChatGPT をサブスクで接続する
LiteLLM には chatgpt プロバイダーがあり、OAuth device code flow で ChatGPT アカウントと連携できます。初回だけブラウザで認証して、トークンをホスト上に永続化しておけばあとは自動です。Pod を再起動しても再認証は不要でした。ただ refresh token なので、長期間経つと再認証が必要になる可能性はあります。
chatgpt: models: - name: "gpt-5.5" - name: "gpt-5.4" - name: "gpt-5.4-mini" - name: "gpt-5.3-codex" tokenHostPath: /var/lib/k8s/litellm/chatgpttokenHostPath で認証トークンを hostPath に永続化しています。
ローカル LLM 側の構成
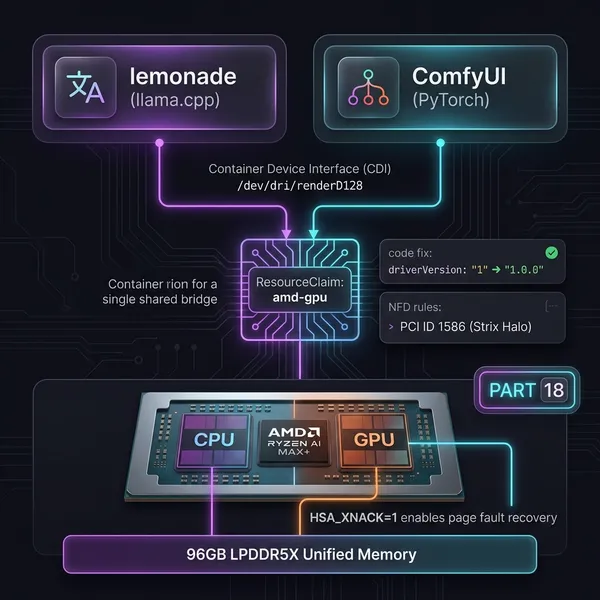
ローカルモデルは Lemonade というサーバーで動かしています。AMD ROCm バックエンドの llama.cpp ラッパーで、OpenAI 互換のエンドポイントを持ちます。今回の環境は Strix Halo(Ryzen AI MAX+)で、GPU と CPU が 128GB のメモリを共有しています。
現在動かしているモデルはこの 3 つです。
Gemma-4-E4B-it-GGUF → 4B、軽量・高速Qwen3.6-35B-A3B-GGUF → MoE、実効 3.5B 相当gemma-4-26B-A4B-it-uncensored → カスタム、26B MoELemonade は複数モデルを LRU スワップしながらホストできます。128GB のメモリがあるので VRAM 不足にはなりにくいです。
全部まとめると一本のエンドポイントになる
inference.homelab.otama-playground.com に向けるだけで、ローカルモデルと ChatGPT のどちらも使えます。クライアント側から見るとモデル名を変えるだけで切り替えられます。
Gemma-4-E4B-it-GGUF-nothink → ローカル・思考モード無効の高速版chatgpt/gpt-5.5 → ChatGPT サブスクリプション-nothink は思考モードを無効にしたエイリアスです。Gemma-4 や Qwen3 系は思考チェーンを生成するのですが、commit メッセージの生成のような軽いタスクには過剰なので、それをオフにした版を別モデル名で生やしています。
ローカルモデルが web 検索を呼ぼうとしたときは SearXNG(自前の検索エンジン)に中継する設定も入れてあります。
opencode との組み合わせも検討中
opencode も OpenAI 互換 API を話せるので、LiteLLM に接続できます。opencode Go はサブスクリプションで API キーが取得できるらしく、これも ChatGPT と同じく費用の見通しが立てやすそうで助かります。
現状の想定はこんな感じです。advisor、設計、レビューのような重いタスクは gpt-5.5、それ以外の作業はローカル LLM。ただこの構成だと Sonnet クラスのモデルが抜けています。opencode で DeepSeek v4 Pro を追加するとその中間が埋まってちょうど良さそうだと思っていて、そこはまだ検討中です。
まとめ
LiteLLM を一枚噛ませることで、ローカル LLM と ChatGPT サブスクリプションを同一エンドポイントで扱えるようになりました。クライアント側からはモデル名を変えるだけで切り替えられます。
ChatGPT をサブスクで接続できるのは思ったより便利で、API 課金を気にせず GPT-5 系を使えるのはコスパが良いです。ローカルモデルの nothink バリアントや SearXNG 連携を組み合わせると、軽いタスクはほぼコストゼロで回せます。opencode との組み合わせはまだ考え中ですが、もし導入したらまた記事にします。
ローカルで ComfyUI も立てているので、いずれ /image/generation エンドポイントも同じ LiteLLM 経由で使えるように設定したいところです。