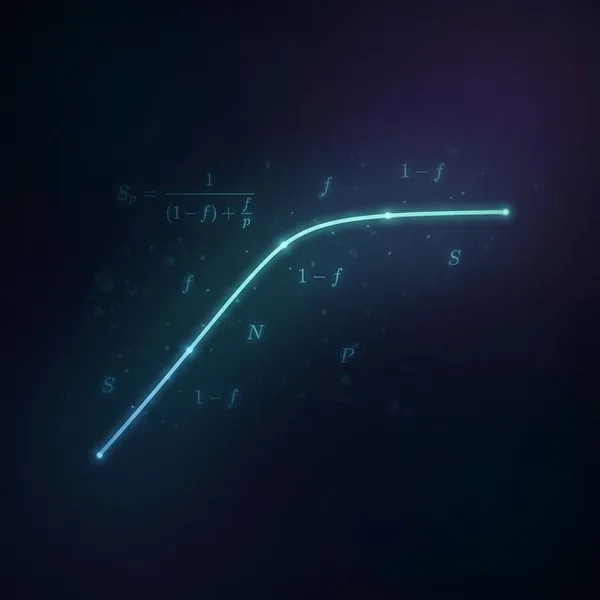はじめに
[!NOTE] この記事は、筆者が鈍器本を読みながら書き殴った個人的な読書メモをAIに食べさせ、ブログ用に読みやすく再構成させたものです。
仕事でアプリケーションのベンチマーキングを行うことになり、「とりあえずこの辺だろう」と『詳解 システム・パフォーマンス 第2版』を買ってみました。
開いてみて驚愕。ページ数が驚異の1782ページ(電子版なのでデバイスによります)もあるじゃないですか。そして中身は方法論やツール、計測タイプの列挙。完全に辞書的に使われることを想定している作りです。
著者のBrendan Gregg氏は「読者が学習のために割ける時間が非常に限られていることがわかっているだけに、私はこの本をできる限り短くするとともに、特定の章にすぐに飛び込んでいけるような構造にまとめようと努力した」と言っていますが、これはさすがに嘘だろと独り言を言ってしまいました(笑)。完全に鈍器です、これ。
全部を真面目に読む時間は到底ないので、今回はパフォーマンス分析の土台となる**「第2章 メソドロジ」**について、後からサッと見返せるように要点を絞って整理しておこうと思います。
1. パフォーマンス分析の基本用語
まずは会話の土台になるキーワードから。このあたりは基本ですね。
- IOPS: ディスクI/Oの1秒あたりの読み書き回数など。
- スループット: データ転送速度や、単位時間あたりの処理量。
- 応答時間 / レイテンシ: 処理にかかる待ち時間や完了までの時間。
- 使用率 / 飽和度: リソースをどれくらい使っているか(使用率)と、あふれて「順番待ち(キューイング)」になっている量(飽和度)。
- ボトルネック: パフォーマンスの限界を決めている、いわゆる「一番遅い部分」。
2. 重要なコンセプトと「落とし穴」
ここからは、実際の分析で意識しておきたい重要な考え方です。
負荷の問題か、アーキテクチャの問題かを切り分ける
これが一番大事かもしれません。
- アプリの処理は軽いのに順番待ちが発生している -> 負荷の問題(台数を増やしてスケーリングで対応)
- CPUはスカスカなのに処理が進まない -> アーキテクチャ(実装)の問題(スレッドのロック待ちなど)
- CPUがいっぱいいっぱいのマルチスレッド処理 -> 負荷の問題
「観測者効果」と「うるさい隣人」に気をつけよう
- 観測者効果: パフォーマンスを計測するツール自体がリソースを食ってしまい、結果を歪めてしまう現象です。JavaならJFRやasync-profilerなど、オーバーヘッドの小さい「今どき」のツールを選びたいですね。
- うるさい隣人(Noisy Neighbor): 同じマシンで動く別のアプリや、クラウド環境で同じ物理サーバーを共有する他テナントの影響でいきなり遅くなる現象です。これらを考慮せずにスループットやレイテンシだけを見ると足元をすくわれます。
いつ分析をやめるか?
ダラダラと分析を続けないことも大切です。「パフォーマンスの低下理由が大部分説明できた」「これ以上分析してもコスパ(ROI)が悪い」と思ったら、潔くやめるのが吉みたいです。
3. 分析のアプローチ(どこから手をつけるか)
OSやアプリケーションを分析する際、主に2パターンの視点があります。
- リソース分析(下から上へ): CPUやメモリなど、各パーツの限界から調べるアプローチ。
- ワークロード分析(上から下へ): アプリケーション側に注目して、スループットやレイテンシを深掘りしていく仕組み。
現場でよくやりがちな**「街灯のアンチメソッド(Topコマンドなど、見やすい・知っている指標だけを見て満足してしまうこと)」や、「当てずっぽうで設定を変えるアンチメソッド」**には要注意。しっかりとした仮説ベースで進めていきたいです。
迷ったらこれ!「USEメソッド」
著者が提唱する最強の初手メソッドです。すべてのシステムリソース(CPU、メモリ、ディスク、ネットワークなど)に対して、以下の3つを順番にチェックします。
- Errors(エラー): まずはエラーが出ていないか?(一番わかりやすい)
- Saturation(飽和度): 処理しきれずに順番待ち(キューイング)が発生していないか?
- Utilization(使用率): リソースがどれくらいビジーか?
あれこれ手を出さず、「まずは全リソースの USE を埋める」と決めておくだけで、分析の迷子が防げそうです。
4. スケーラビリティとリソースごとの「壊れ方」
負荷が増えた時、システムはどう限界を迎えるのかを知っておくのも重要です。
- CPU: 使用率が100%になるとコンテキストスイッチが増大し、じわじわとパフォーマンスが落ちていく。
- メモリ: 足りなくなるとスワップ(ディスクへの退避)が始まり、急激に破綻する。
- ディスク: 順次処理(キューイング)なので、負荷が増すと待ち時間が一気に伸びて急激な遅延を起こす。
こうした傾向を「待ち行列理論」などの数学モデルにあてはめて予測することで、本番環境で急激にシステムが崩壊するのを未然に防ぐことができるわけですね。
5. 見落としがちな「外れ値」と「Unknowns」
平均値だけを見ていると痛い目を見ます。
- 外れ値に注意: ほとんどが10msで終わる処理の中に、たまに1000msかかる処理が混ざっている場合、平均値だけだと気づけないことがあります(中央値や99パーセンタイル値を見るのが定石です)。
- Unknown-Unknowns: 「自分が何を分かっていないかさえ分かっていない」恐怖の状態です。まずは計測を始めてシステムを知る(Known-Knownsを増やす)ことで、初めて「あ、ここも調べなきゃ」という気づきが得られるみたいです。
6. 開発者の心に刻む「パフォーマンスマントラ」
パフォーマンスを改善(チューニング)するときに、効果が高い順に並べた7つの標語(呪文)です。これも現場ですぐに使えそうな考え方ですね。
- するな(不要な仕事をそもそもなくす)
- してもいいが二度するな(キャッシュを活用する)
- 減らせ(ポーリングなどの頻度を下げる)
- 先に延ばせ(非同期処理や遅延書き込みにする)
- 見られていないときにせよ(バックグラウンドやピーク外で処理する)
- 同時並行でせよ(マルチスレッド化する)
- 安上がりにせよ(ハードウェアを課金して殴る)
コードを書くとき、「これは『二度している』からキャッシュしよう」と思い出せるようにしたいです。
おわりに
かなり分厚い本ですが、第2章のメソドロジ(方法論)だけでも、パフォーマンスチューニングの勘所がたくさん詰まっていました。とくに「見えやすい指標だけを追うな」「リソースごとの壊れ方の違いを知れ」といった実践的なメソッドは、現場ですぐに意識できそうです。
今後も「なぜか想定スループットが出ない」といったトラブルに遭遇したときは、このメモをサッと見返して、アーキテクチャの問題なのか、外部要因なのかを冷静に分析していこうと思います!