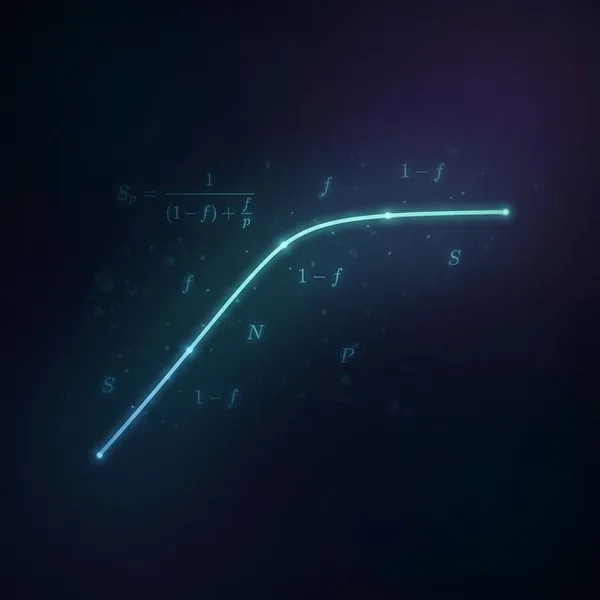Introduction
[!NOTE] This article was generated by feeding my chaotic, personal reading notes of this massive textbook into an AI to restructure them into a readable blog post.
I recently had to perform some application benchmarking for work, so I decided to pick up Systems Performance: Enterprise and the Cloud, 2nd Edition, figuring it would be a good starting point.
When I opened it, I was shocked. The page count is a staggering 1782 pages (on standard digital readers). It’s essentially a brick or a dictionary.
I definitely don’t have the time to read the entire thing cover-to-cover, so I’ve decided to pull out just the essential parts. Today, I’m organizing the core concepts from “Chapter 2: Methodology” into a quick, skim-friendly cheat sheet so I can easily look back at the foundational performance concepts later.
1. Basic Performance Terminology
First, let’s establish the common language for performance analysis. These are the basics:
- IOPS: Input/Output Operations Per Second (e.g., how many reads/writes a disk performs per second).
- Throughput: The speed at which work gets done, like data transfer rates or operations per second.
- Response Time / Latency: The wait time and execution time required to complete an operation.
- Utilization / Saturation: How much of a resource is actively being used (utilization), and how much work is overflowing and waiting in line (saturation).
- Bottleneck: The specific resource that is artificially limiting the system’s overall performance.
2. Crucial Concepts and Pitfalls
Here are the most important concepts to keep in mind during actual analysis.
Isolating Load vs. Architecture
This is probably the most crucial distinction you can make:
- The app is lightweight, but there’s massive queuing -> Load Problem (Fix by scaling horizontally).
- CPUs are mostly idle, but operations are stalling -> Architecture/Implementation Problem (e.g., thread lock contention).
- Multithreaded app with 100% CPU utilization -> Load Problem.
The “Observer Effect” and “Noisy Neighbors”
- Observer Effect: The phenomenon where the performance profiling tools themselves consume resources and negatively warp your test results. For Java, you definitely want to rely on modern, low-overhead tools like JFR or async-profiler.
- Noisy Neighbors: When other applications on the same machine—or other tenants sharing your exact physical server in a cloud environment—suddenly cause your performance to tank. If you blindly look only at throughput without considering external perturbations, you’ll be completely misled.
When to Stop Analyzing?
It’s important not to get stuck in an endless loop of analysis. The author notes that it’s best to stop when “the vast majority of the performance degradation is explained” or when “the expected ROI of further analysis drops below the simple cost of the analysis itself.”
3. Analytical Approaches (Where to Start)
When breaking down a whole OS and application stack, there are generally two pathways:
- Resource Analysis (Bottom-Up): Starting from physical hardware limits (CPU, memory, disk utilization/saturation).
- Workload Analysis (Top-Down): Starting by drilling down into application-level metrics, specifically throughput and latency.
Be extremely careful to avoid common traps like the “Streetlight Anti-method” (only looking at metrics you understand or variables that are easy to measure, like top) or the “Random Change Anti-method” (blindly guessing and tweaking settings). Always base your investigations on logical hypotheses!
When in Doubt: The “USE Method”
This is the ultimate entry-level method coined by the author. For every single system resource (CPU, memory, disk, network, etc.), you systematically check the following three metrics in order:
- Errors: Are there any errors occurring? (Always the easiest to catch).
- Saturation: Is work piling up waiting to be handled (queueing)?
- Utilization: How busy is the resource?
By simply deciding to “fill out the USE checklist for all components” before doing anything else, you can completely prevent yourself from getting helplessly lost in the weeds during an analysis.
4. Scalability and How Resources “Break”
It’s vital to know exactly how different system resources hit their absolute limits.
- CPU: When utilization hits exactly 100%, context switching spirals, causing performance to degrade gradually but painfully.
- Memory: When exhaustion occurs, swapping (paging to disk) violently kicks in, causing the system to catastrophically fail or freeze rapidly.
- Disk: Because disk execution is sequential (queueing), intense loads instantly cause queues to pile up, creating a vicious cliff of sudden latency drops.
By plugging these behaviors into mathematical models like “Queuing Theory”, you can theoretically predict and prevent your production environment from catastrophically collapsing under sudden load spikes.
5. Overlooked “Outliers” and “Unknowns”
Looking exclusively at raw averages will eventually destroy you.
- Beware of Outliers: If 99% of tasks finish in 10ms, but a rare few take over 1000ms, a simple average will completely hide the problem. You absolutely must look at medians or 99th percentile metrics.
- Unknown-Unknowns: The terrifying state where “you don’t even know what you don’t know.” The only way to combat this is to just start measuring. Building baseline knowledge (Known-Knowns) is the only way to eventually stumble upon the blind spots you need to investigate next.
6. The “Performance Mantra” Every Developer Should Memorize
When actively improving (tuning) performance, here are 7 dictums (almost like a spell) ranked in order of how effective they usually are. This is a brilliant mindset to immediately adopt at work.
- Don’t do it (Eliminate unnecessary work entirely).
- Do it, but don’t do it again (Cache aggressively).
- Do it less (Reduce the frequency of polling/checks).
- Do it later (Utilize asynchronous processing or lazy writes).
- Do it when they’re not looking (Run tasks in the background or during off-peak hours).
- Do it concurrently (Multithread everything).
- Do it cheaper (Throw more hardware at the problem).
When writing code, I really want to catch myself and think, “Wait, I’m ‘doing this again’—I should cache this!”
Conclusion
Despite being a massive textbook, just the Methodology chapter alone is absolutely packed with highly practical tuning wisdom. Concepts like avoiding the “Streetlight Anti-method” and understanding exactly how different resources fundamentally fail under pressure are things I can apply immediately.
Whenever I eventually run into another brutal issue where “throughput just won’t scale,” I’m definitely pulling this cheat sheet back out to calmly isolate whether it’s an architectural wall or just a noisy external neighbor!