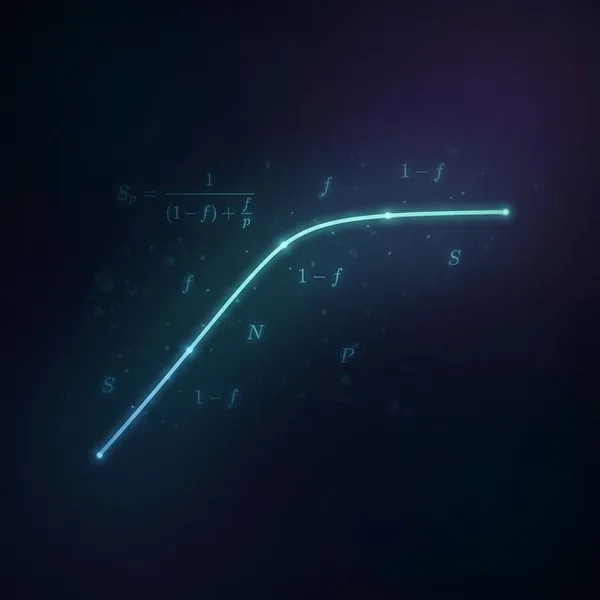はじめに
[!NOTE] この記事は、筆者が鈍器本を読みながら書き殴った個人的な読書メモをAIに食べさせ、ブログ用に読みやすく再構成させたものです。
これまで「2章 メソドロジ」や「5章 アプリケーション」など、実践的なパフォーマンス分析の手法をまとめてきましたが、今回は基礎に立ち返って「3章 オペレーティングシステム」です。
「OSの基礎なんて今更…」と読み飛ばしたくなる章ですが、いざ本番環境で「謎のレイテンシ」や「原因不明のCPU消費」に直面したとき、OSの裏側のふるまいを理解していないと、そもそもアタリ(仮説)をつけることすらできません。
今回も、細かすぎるカーネルの歴史やパラメータ一覧は思い切って省き、**「現場でパフォーマンスを語るなら絶対に知っておきたいOSとカーネルの仕組み」**だけを抽出してチートシートにしました。
1. 意外と重い「システムコールの壁」
アプリケーションがOSに頼み事をする(システムコール)とき、裏では「モードスイッチ」という見えないコストが発生しています。
アプリケーションは通常、安全な「ユーザーモード」で動いていますが、ファイルへの読み書き(read / write)やネットワーク通信を行うときには、特権を持つ「カーネルモード」に切り替わる(モードスイッチする)必要があります。
- セキュリティ対策によるさらなる遅延: Linuxカーネルに「KPTI(メルトダウン脆弱性対策)」が導入されて以降、システムコールやコンテキストスイッチのたびにCPUのキャッシュ(TLB)がフラッシュされるようになり、昔よりもシステムコールのコストが目に見えて重くなりました。
- 回避策(カーネルバイパス): このオーバーヘッドを嫌い、最近のネットワーク処理(DPDKなど)では、OSのカーネルを完全にバイパスしてアプリケーションが直接デバイスを触る技術まで使われるようになっています。
やたらと細かいI/Oを繰り返すアプリが遅い理由は、この「見えない壁」を何度も往復しているからです。
2. 「CPUは空いているのに遅い」理由(プロセスの状態)
プロセス(スレッド)が遅いとき、それは「CPU上で計算している」か、「CPUが空くのを待っている」か、「I/Oなどを待って寝ている」かのどれかです。OSのスケジューラはこの状態を管理しています。
パフォーマンス分析で真っ先に切り分けるべきなのが、アプリのワークロード(仕事)の性質です。OSは以下の2つを厳密に見分けています。
- CPUバウンド: ひたすら計算を行う仕事。CPUリソースがボトルネックになる。
- I/Oバウンド: ネットワークやディスクの応答を待つことが多い仕事。CPUはあまり使わない。
アプリが遅いとき、「CPU使用率が低いからCPUの問題ではない」と即断するのは危険です。 実は、OSのスケジューラによって「実行可能(いつでも走れるが、CPUの順番待ちで止められている状態)」にされているのか、それともネットワークやディスクの応答を待って「スリープ(off-CPU状態で寝ている)」しているのかを見極める必要があります。 「CPUはスカスカなのに遅い」という現象の大半は、この「I/O待ちによるスリープ」か「ロック待ち」が原因です。
3. OSの賢い手抜き術「COW」と「デマンドページング」
OSは、本当に必要になるギリギリの瞬間まで、メモリの割り当てやデータのコピーをサボる(遅延させる)ようにできています。これを知らないとメモリ指標に騙されます。
- COW(コピーオンライト): プロセスを複製(
fork)したとき、OSはメモリを丸ごとコピーしません。両方のプロセスで同じメモリを共有しておき、**「どちらかがデータを書き換えようとした瞬間に、初めて別々のコピーを作る」**という戦略をとります。 - デマンドページング: アプリが「メモリをくれ」と要求して仮想メモリが割り当てられても、その瞬間に物理メモリが確保されるわけではありません。**「その仮想メモリに初めて書き込みを行った瞬間(オンデマンド)」**に物理メモリが割り当てられます。
「メモリを確保したはずなのに、物理メモリの空きが減っていない」といった事象は、この仕組みによるものです。
4. 「ディスクに書いた」は本当か? 幾重にも重なるキャッシュ
ディスクI/OはCPUやメモリに比べて絶望的に遅いため、OSはありとあらゆる手段(キャッシュ)を使ってディスクへのアクセスを回避しようとします。
アプリケーションが「ファイルに書き込んだ」と思っても、実際にはメモリ上のキャッシュに書かれただけで、ディスクには届いていないことがよくあります。OSのI/Oスタックには以下のようなキャッシュが何層にも重なっています。
- アプリケーションキャッシュ
- iノードキャッシュ(メタデータ用)
- ページキャッシュ(ファイルシステムキャッシュ)
- ディスクコントローラのキャッシュ etc…
ベンチマークで「ディスクが爆速だ!」と思っても、それは単に**「手前のページキャッシュの速度を測っていただけだった」**というオチが非常に多いので要注意です。
5. パフォーマンスを殺す「スワッピング」の罠
同じ「メモリのページをディスクに書き出す」動作でも、ファイルシステム由来のものと、アプリケーション由来のもの(スワッピング)では深刻度がまったく違います。
- ファイルシステムページング(良いページング): ディスクから読み込んだファイルのキャッシュを捨てる動作。また読み直せばいいだけなので正常な動作です。
- 無名ページング / スワッピング(悪いページング): アプリケーションのヒープやスタックなど、ファイルと結びついていない「無名メモリ」が足りなくなり、強制的にスワップデバイス(ディスク)に退避される動作。これが発生すると、アプリはディスクI/Oのレイテンシに巻き込まれ、パフォーマンスが壊滅します。
Linuxではこの「無名ページング」のことを指して「スワッピング」と呼びます。これが発生し始めたら赤信号です。
6. 謎のCPU消費「%si(ソフトIRQ)」の正体
top コマンドを見たとき、ユーザー処理(%us)でもシステム処理(%sy)でもなく、%si (Soft Interrupts) がCPUを食っていることがあります。これは「割り込みの後半戦(後回しにされた処理)」です。
ネットワークパケットの到着やディスクI/Oの完了など、デバイスからの割り込み(ハードウェア割り込み)は一刻も早く終わらせる必要があります。そのためLinuxは処理を2つに分けます。
- 上半分: 割り込みを止めて、一瞬で終わらせる最小限の処理。
- 下半分(ソフトIRQ): ネットワークパケットのプロトコル処理など、時間のかかる重い処理。これを後回しにしてスケジュールします。
ネットワークトラフィックが激しいシステムなどで「謎のCPU消費」を見つけたら、このソフトIRQが原因であることが多いです。
7. プロファイリングでハマる「2つのスタック」
スレッドは「ユーザー用」と「カーネル用」の2種類のスタックを持っています。プロファイリングをするときは、両方を取得しないと全容が見えません。
システムコールの実行中、ユーザーレベルのスタック(アプリ側の履歴)はピタッと止まり、そこから先はカーネルレベルのスタックが使われます。
「アプリがどこで時間を食っているか」を調べるために perf などを回す場合、ユーザー側のスタックしか見ていないと、カーネルの奥深く(ディスクI/Oなのか、ネットワークか、ロック待ちか)が完全にブラックボックスになってしまいます。
8. 現代パフォーマンス分析の主役「拡張BPF」
従来のツールでは重すぎて本番環境では使えなかった詳細なイベント分析を、安全かつ超低負荷で実行できるようになった「魔法」の技術です。
この本の大部分の分析ツールの心臓部になっているのが、この 拡張BPF (eBPF) です。 昔は、カーネル内で起きたイベントをすべてユーザー空間にコピーして集計していたため、とんでもない負荷がかかっていました。
- カーネル内で安全にプログラムを動かす: BPFは、ユーザーが書いた小さな集計プログラムを「カーネルの内部(仮想マシン上)」で直接動かします。これにより、**「カーネル内でヒストグラムの計算まで終わらせて、最終結果だけをユーザー空間に返す」**といった離れ業が可能になりました。
「本番環境でシステムの奥底をリアルタイムに覗き見する」というこの本の核となるアプローチは、BPFの存在なしには語れません。
おわりに
この章を読むと、普段私たちが何気なく書いているアプリケーションのコードが、OSのカーネル内部でどれほど複雑な「切り替え」や「メモリのやりくり」を経て実行されているかがよく分かります。
特に「幾重にも重なるキャッシュレイヤ」や「スワッピングとページングの違い」、「ソフトIRQの正体」といった基礎知識は、今後「なぜ想定したスループットが出ないのか?」「ボトルネックは負荷なのかアーキテクチャなのか?」を考察するときの、非常に強力な仮説構築の武器になるはずです。
OSの基礎を押さえたところで、次はいよいよ「CPU」や「メモリ」など、個別のリソースの深掘りに進んでいきたいと思います!