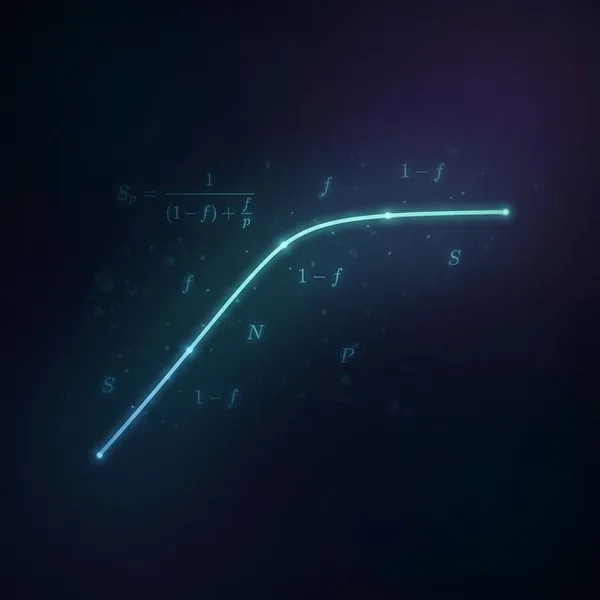はじめに
[!NOTE] この記事は、筆者が鈍器本を読みながら書き殴った個人的な読書メモをAIに食べさせ、ブログ用に読みやすく再構成させたものです。
これまで「2章 メソドロジ」「5章 アプリケーション」とパフォーマンス分析の土台を整理してきましたが、今回はシステムの構成を変えたときの評価などに欠かせない「12章 ベンチマーキング」をまとめます。
著者が**「ベンチマークの結果が誤解を招くことは業界ではよくあること」**と断言しているように、ベンチマークを正しく実行して素直に解釈するのは驚くほど困難だそうです。
今回も、分析の罠にハマらないためのポイントや、現場で意識したい技術的な詳細のハイライトだけを抽出して、サクッと見返せるチートシートにしました。
1. なぜベンチマークは「大嘘」をつくのか
ベンチマークツールが出した数字をそのまま信じるのは非常に危険です。本書には「避けるべきアンチパターン」が16個も紹介されていますが、特に現場でやりがちなのは以下のケースです。
- 場当たり的な計測: 「ディスクI/Oをテストしているつもりが、実はOSのファイルシステムキャッシュの速度を測っていただけだった」というのは超典型例です。(1Gbpsのネットワーク越しで3Gbpsのスループットが出ているなら、間違いなく手元のキャッシュを計測しています)。
- エラーの無視: 「ファイアウォールで通信が全ブロックされていて、単に一瞬で『タイムアウトした時間』を測っていただけなのに、テスト成功&超高速として報告してしまった」といった笑えないミスも十分起こりえます。
- ばらつきの無視: ツールで「平均秒間500リクエスト」のように一定のペースで負荷をかけてテストしてしまう罠です。現実のシステムは、一瞬のバースト(スパイク)でキューイングが発生して遅延することが多いので、平均ペースのテストは本番の厳しさをシミュレートできていません。
ツールを実行して「よし速い!」と分析を終わらせるのではなく、「本当にテストしたいものをテストできているか」を常に疑う姿勢が求められます。
2. 実環境のログをそのまま流す「リプレイの罠」
本番環境のクライアントによるアクセスログ(トレース)を、そのままターゲットシステムで再実行する「リプレイ」手法は、一見完璧なテストに思えます。しかし、ここにも大きな罠があります。
たとえばシステムのディスクアクセスが遅くなった分、ファイルシステムの「キャッシュを16倍に増やした」新しい検証システムを作ったとします。ここに旧環境のログをそのまま流し込んでも、新環境の「キャッシュにあたる確率(ヒット率)」などの効果が正しくシミュレートされず、まったく当てにならない低い結果が出てしまうのです。
3. 優れたベンチマークが満たす「6つの条件」
では、逆に「良いベンチマーク」とは何でしょうか? 著者は以下の6つのエッセンスを満たすべきだとしています。
- 反復可能:何度やっても同じ結果になり、比較できること
- 観察可能:実行中にパフォーマンスツールで中身を分析できること
- ポータブル:他社のシステムや別バージョンでも同じように動かせること
- 容易なプレゼンテーション:誰が見ても結果がスッと理解できること
- 現実的:顧客が感じる「リアル」を反映していること
- 実行可能:開発者がサクッとテストを変更して再実行できること
これらに「価格/パフォーマンス比(コスパ)」を加えたものが、システム導入を評価する際の最強の武器になります。
4. まずい計測を防ぐ「アクティブベンチマーキング」
初心者は一番やってはいけない**「パッシブベンチマーキング(ツールの実行ボタンを押して、あとはただ待つだけの手法)」**をやりがちです。
本書が強く推奨しているのは、システムが動いている間に可観測性ツールで中身を覗き見する**「アクティブベンチマーキング」**です。
ツールに騙されないために(bonnie++の教訓)
あるディスクテストツール(bonnie++)を実行中、裏で動的トレース(strace)を覗いてみたところ、一向にディスクアクセスが行われず、1バイトずつの書き込みがループしているだけだった…という事例が紹介されています。これはlibcのバッファリングをテストしていただけであり、アクティブに観察しなければ一生気づけない罠でした。
なにかおかしいなら「CPUプロファイリング」
ベンチマーク中になぜか異常に遅いと感じたら、CPUのプロファイリング(フレームグラフなど)を取得します。すると、「ZFSの特定のリソース制限関数がひたすら待ちを発生させていて、ベンチマークの足を意図的に引っ張っていた(スロットリング)」といった原因がひと目で判明することがあります。
5. スケーラビリティを見極める「ランプ負荷」
ベンチマークを行う際、いきなりMAXの負荷をかけるのではなく、スレッド数や要求数を「少しずつ段階的に(ランプ)」増やしていく手法が有効です。どこでパフォーマンスが頭打ちになるかをグラフ化することで、システムのスケーラビリティの限界が見えてきます。
- レイテンシの跳ね上がりに注意: 「限界まで負荷をかけたら100万IOPS出せた!」と喜んでも、その限界付近では**レイテンシが跳ね上がって実用的な応答速度ではなくなっている(平均50msなど)**ことがよくあります。「どこまでなら許容できるレイテンシを保ちつつスケールできるか」を見極めるのが重要ですね。
6. 結果を疑うための「6つのチェックリスト」
最後は、自分や他人が出したベンチマーク結果を評価する際に、必ず自分に問いかけるべき6つの項目です。
- なぜ倍ではないのか?(負荷を倍にしても結果が倍にならないなら、何がボトルネックになっているか?)
- テストは限界を超えていないか?(ネットワーク帯域など、物理的な限界以上の異常な数値が出ていないか?)
- テストはエラーになっていないか?(実はタイムアウトを測っていただけではないか?)
- テストは再現されるか?(たまたま出た数値ではなく、結果は安定しているか?)
- 意味のあるテストか?(本番環境の実際のワークロードと合致しているか?)
- 本当にテストしたのか?(設定ミスで何もしていない状態ではないか?)
これを知っているだけで、怪しいベンチマーク結果に騙される確率がグッと下がります。
おわりに
この章を読むと、ベンチマーキングという仕事が単なる「ツールの実行作業」ではなく、「システムが今、裏でどんな動きをしているか」を疑い、リアルタイムに観測する非常に高度なデバッグ作業なのだと痛感させられます。
今後、システム移行や新しいツールの検証などでベンチマークを取る際は、決して「ツールの数値をそのまま信じる」ことはせず、今回整理した「6つのチェックリスト」や「ランプ負荷」の観点を使ってチェックを行っていこうと思います。
統計というのは、ちょっと条件をいじるだけで簡単にハックが可能になってしまうものです。自分があくどい数字を出さないためにも、そして他人の怪しい結果に騙されないためにも、実験方法が本当に正しいかを問う姿勢を忘れないようにしたいですね!