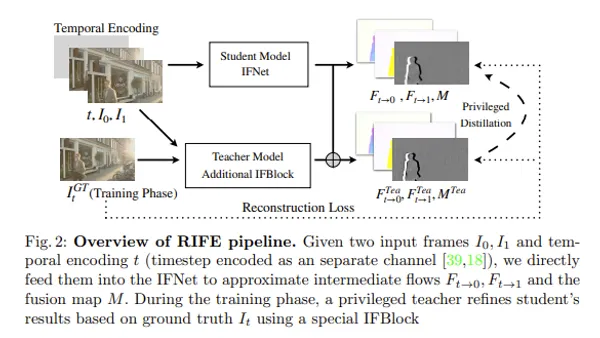
Stream Diffusion is technology enabling high-quality image generation in real time. It achieved amazing speed of maximum 91.07fps with RTX 4090, which is performance improvement of about 59.56 times compared to conventional method.
In this article I briefly explain how Stream Diffusion enables real-time image generation.
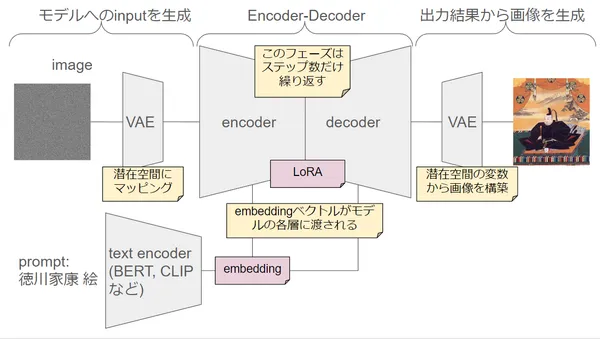
Note: Please understand this is a note to grasp overview and does not treat mathematical parts.
About Stream Diffusion

We introduce StreamDiffusion, a real-time diffusion pipeline designed for interactive image generation. Existing diffusion models are adept at creating images from text or image prompts, yet they often fall short in real-time interaction. This limitation becomes particularly evident in scenarios involving continuous input, such as Metaverse, live video streaming, and broadcasting, where high throughput is imperative. To address this, we present a novel approach that transforms the original sequential denoising into the batching denoising process. Stream Batch eliminates the conventional wait-and-interact approach and enables fluid and high throughput streams. To handle the frequency disparity between data input and model throughput, we design a novel input-output queue for parallelizing the streaming process. Moreover, the existing diffusion pipeline uses classifier-free guidance(CFG), which requires additional U-Net computation. To mitigate the redundant computations, we propose a novel residual classifier-free guidance (RCFG) algorithm that reduces the number of negative conditional denoising steps to only one or even zero. Besides, we introduce a stochastic similarity filter(SSF) to optimize power consumption. Our Stream Batch achieves around 1.5x speedup compared to the sequential denoising method at different denoising levels. The proposed RCFG leads to speeds up to 2.05x higher than the conventional CFG. Combining the proposed strategies and existing mature acceleration tools makes the image-to-image generation achieve up-to 91.07fps on one RTX4090, improving the throughputs of AutoPipline developed by Diffusers over 59.56x. Furthermore, our proposed StreamDiffusion also significantly reduces the energy consumption by 2.39x on one RTX3060 and 1.99x on one RTX4090, respectively.

StreamDiffusion is a new pipeline realizing real-time image generation. Feature is changing conventional sequential noise removal to batch processing, and it seems to lead to name of Stream Diffusion. Since it achieved maximum 91.07fps with RTX 4090 as final result, it is quite fast compared to conventional image generation model. (Throughput improvement of 59.56 times compared to conventional method)
Main features of Stream Diffusion are follows.
- Stream Batch
- Convert conventional sequential denoise processing to batch processing. High-speed stream processing possible.
- Residual Classifier-Free Guidance (RCFG)
- By reducing denoise calculation of negative condition to 1 time or 0 time, calculate cost is reduced largely.
- Input-Output Queue
- Queue to hold input and output of image generation model. Pre-processing and post-processing can be processed in parallel by separate thread.
- Stochastic Similarity Filter
- Evaluate similarity of continuous inputs, preventing wasteful use of GPU.
- Pre-computation Procedure
- Calculate parts that can be calculated in advance.
- Tiny AutoEncoder
- Replace VAE with one optimized for image.
- Model Acceleration
- Use TensorRT
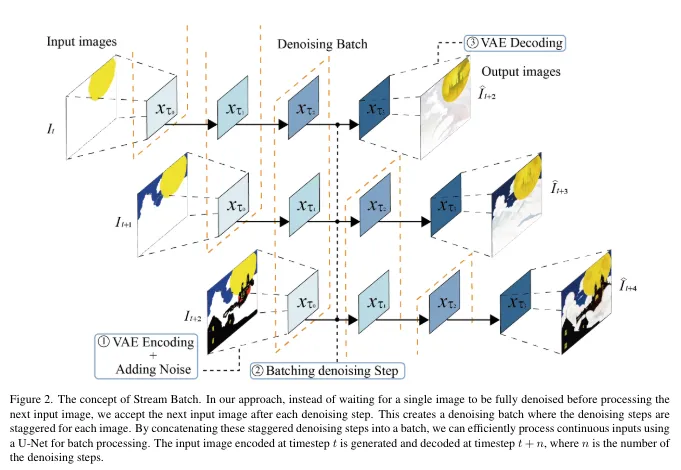
Stream Batch
Stream Batch strategy is method converting sequential denoise processing to batch processing. By this, parallelization of processing becomes possible, realizing high throughput stream processing while reducing waiting time.
In conventional model, since each step is executed in order, there was long waiting time. In Stream Batch strategy, batch process denoise steps of multiple images at once, and parallelize. By processing at once, waiting time is minimized and high speed processing becomes possible. Furthermore by parallelization, calculation resource of GPU can be used efficiently, and this also contributes to speedup.
Below is pipeline of Stream Batch cited from paper. Orange dotted line probably indicates chunk processed simultaneously.
Residual Classifier-Free Guidance (RCFG)
RCFG is method aiming to improve precision while reducing calculation cost by optimizing denoise processing using positive prompt and negative prompt. Specifically does things like following.
- Enhancement of Positive Prompt
- RCFG enhances effect of positive prompt same as conventional Classifier-Free Guidance (CFG).
- By using Virtual Residual Noise, enhance conditioning effect of positive prompt, reducing additional U-Net calculation.
- Calculation Reduction of Negative Prompt
- RCFG calculates residual noise of negative prompt only at first denoise step, and uses virtually estimated residual noise (Virtual Residual Noise) in subsequent steps.
- By this, maintain conditioning effect of negative prompt while reducing calculation cost.
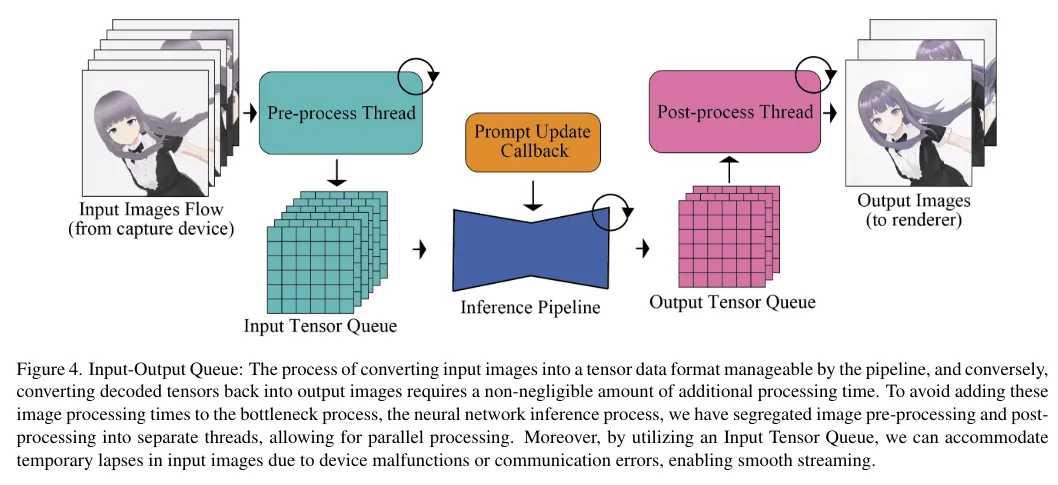
Input-Output Queue
Input-Output Queue is queue to hold input and output of image generation model as name suggests. By preparing queue, pre-processing and post-processing of image can be processed in parallel by separate thread, and overall throughput can be improved. Usually pre-processing and post-processing are done in sequential processing, so it was one of causes of slow image generation speed, but this bottleneck was resolved by queue.
Specifically following queues are used.
- Input Tensor Queue
- Queue to process input data in batch unit. Each input data is added to queue in order, and when reaching certain number (batch size), batch processing starts.
- Output Tensor Queue
- Queue to hold output data from model. Tensor in output queue is taken out in order, and post-processing is performed.
Below is configuration of Input-Output Queue brought from paper.
Stochastic Similarity Filter (SSF)
Stochastic Similarity Filter (SSF) is method to reduce unnecessary calculation load in diffusion model and realize efficient use of GPU resource. Especially when input images are continuous or change is small, by skipping calculation for images with high similarity, calculation resource is saved.
As actual processing, similarity (probability to skip) is evaluated before entering image generation processing, and based on this probability, it is decided whether to skip processing of VAE encode, U-Net, VAE decode. If skipping, process of current input image is skipped, and previous reference frame is used as is. If not skipping, process current input image as usual, and save that result as next reference frame.
Pre-computation Procedure
Pre-computation procedure is method to calculate parts that can be calculated in advance to optimize performance of diffusion model. By this, real-time processing speed improves, and efficient use of calculation resource becomes possible.
Specifically does things like below.
- Cache of embedding
- Calculate embedding in advance and save in cache. By using this cache, need to re-calculate embedding for each frame is eliminated.
- Cache of Gaussian noise
- Sample Gaussian noise used in each denoise step in advance and save in cache. By this, while giving different noise at each time step, consistent noise can be used between each frame.
- Cache of noise strength coefficient
- Calculate noise strength coefficient and for each denoise step in advance, and save in cache. By this, need to re-calculate these values for each frame is eliminated, and calculation efficiency improves.
Tiny AutoEncoder
Tiny AutoEncoder is lightweight autoencoder designed to realize high efficiency image encode and decode in diffusion model. By this, while reducing calculation load largely compared to normal autoencoder, high-speed image generation becomes possible.
By changing VAE to model optimized (shallow layer) for compression of image, it enabled to compress image data to low dimension (latent space) effectively.
Model Acceleration
Speedup by constructing U-NET and VAE with TensorRT.
Note: TensorRT is tool kit provided by NVIDIA, optimizing neural network model. (Don’t know specifically)
Final Architecture
Architecture including everything explained so far is image below.

Conclusion
Feeling after reading is that rather than paper of new model, it feels like collection of techniques to speed up inference of image generation model. Maximum 91.07fps with RTX4090 is amazing, and I feel real-time image generation is becoming reality, or almost realized. Remaining is perfect if spec of necessary VRAM etc. drops.
In future, by further tuning and optimization proceeding, I expect full function image generation model becomes available in mobile devices like smartphone. Application destinations like photo editing app and interactive art are considered, but I am looking forward to how technology of image generation evolves and blends into our daily life.
Since papers read around Stable Diffusion are summarized in following article, please utilize if interested.

Stable Diffusion関連の論文解説記事のリンク集。画像生成・動画生成の基礎モデルから応用技術まで論文ベースで解説。