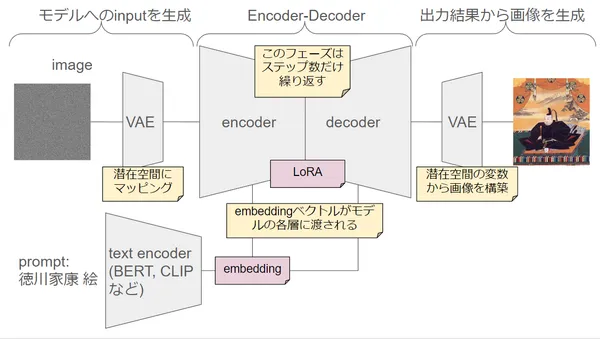
This time I introduce AnimateDiff. AnimateDiff is a model that extends image generation model (Stable Diffusion) and learned to generate video. Since it is almost unchanged from original image generation model, it can generate video quite lightly. AnimateDiff has function that allows users to customize animation based on parameters and conditions they specify. If research on such technologies advances further, it will lead to animation studios and individual creators producing high-quality animation quickly and efficiently, so it is expected in various fields such as game development and advertisement production.
In this article, I will investigate mechanism of AnimateDiff.
About AnimateDiff

With the advance of text-to-image (T2I) diffusion models (e.g., Stable Diffusion) and corresponding personalization techniques such as DreamBooth and LoRA, everyone can manifest their imagination into high-quality images at an affordable cost. However, adding motion dynamics to existing high-quality personalized T2Is and enabling them to generate animations remains an open challenge. In this paper, we present AnimateDiff, a practical framework for animating personalized T2I models without requiring model-specific tuning. At the core of our framework is a plug-and-play motion module that can be trained once and seamlessly integrated into any personalized T2Is originating from the same base T2I. Through our proposed training strategy, the motion module effectively learns transferable motion priors from real-world videos. Once trained, the motion module can be inserted into a personalized T2I model to form a personalized animation generator. We further propose MotionLoRA, a lightweight fine-tuning technique for AnimateDiff that enables a pre-trained motion module to adapt to new motion patterns, such as different shot types, at a low training and data collection cost. We evaluate AnimateDiff and MotionLoRA on several public representative personalized T2I models collected from the community. The results demonstrate that our approaches help these models generate temporally smooth animation clips while preserving the visual quality and motion diversity. Codes and pre-trained weights are available at https://github.com/guoyww/AnimateDiff.

Overview of AnimateDiff
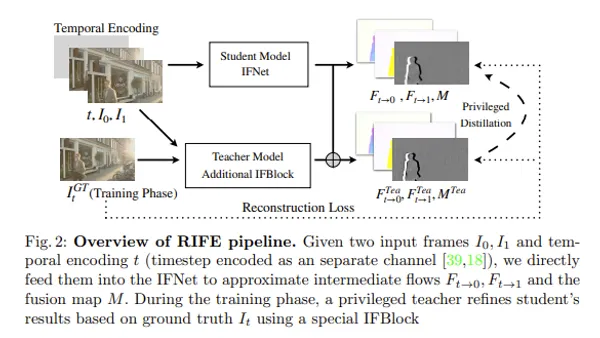
AnimateDiff is a model that enabled video generation by extending based on Stable Diffusion model. Stable Diffusion is a powerful diffusion model bringing high-precision results in image generation tasks, characterized by process of reconstructing data through sequential removal of noise. (Around here is explained in article below)

>-
AnimateDiff extends this Stable Diffusion model, possessing ability to generate high-quality animation while maintaining temporal consistency and smoothness between continuous frames. I explain below by what method this is realized.
Features of AnimateDiff
In AnimateDiff, it is realized by two approaches: extension of Stable Diffusion model and ingenuity of learning method. First,
Extension of Model
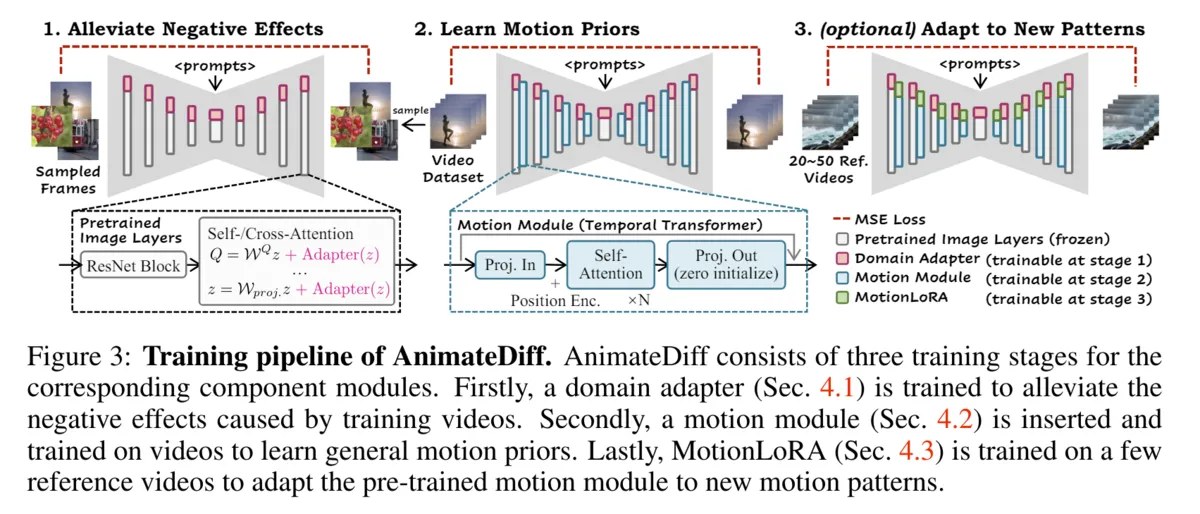
Remodel Stable Diffusion for video using three types of extensions: Domain Adapter, Motion Module, and Motion LoRA.
Domain Adapter
- Domain Adapter is so-called LoRA. It has structure similar to LoRA and is added to Stable Diffusion model and learned to fill distribution difference between domains (in this case difference in quality between image dataset and video dataset).
- By this, it is said to be able to effectively integrate information between different datasets while maintaining different animation styles and consistency between frames.
Note: If you don’t know what LoRA is, it is explained in article below so please read if you like.
>-
Motion Module
- Add module incorporating Transformer to learn consistent movement and change in time series. By this, smooth movement is realized.
- Motion Module is added in series after each layer of Stable Diffusion.
- This module receives input converted to 5D, and processes with Temporal Transformer proposed by author. After processing, return shape of tensor to original and pass to layer of Stable Diffusion.
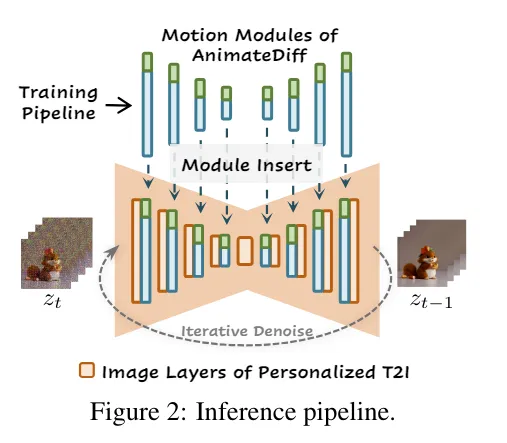
Motion LoRA
- Simply put, it is LoRA added to layer of Motion Module. Nothing particularly characteristic.
Learning Method
AnimateDiff learns while extending model midway in following 3 stages. By this, it is possible to make model learn time axis information gradually while utilizing spatial information held by model learned for image.
- Add Domain Adapter to each layer, and learn only added part. (Weight of original model is fixed)
- Adjust model learned for image for video dataset
- Add Motion Module to each layer and learn.
- Learn motion
- (Optional) Add Motion LoRA to each layer of model, and learn specific movement with few videos.
Conclusion
AnimateDiff is a new technology enabling video generation while utilizing powerful image generation ability of Stable Diffusion model. By extensions like Domain Adapter, Motion Module, Motion LoRA and devised learning method, it became possible to generate high-quality animation lightly. I expect such technology will evolve further in future, realizing more diverse animation styles and high-precision movements.
Since result of actually generating is posted in article below, please look if you like.
>-
Since papers read around Stable Diffusion are summarized in following article, please utilize if interested.
Stable Diffusion関連の論文解説記事のリンク集。画像生成・動画生成の基礎モデルから応用技術まで論文ベースで解説。