シリーズ
AI & Creativity
3分で読了
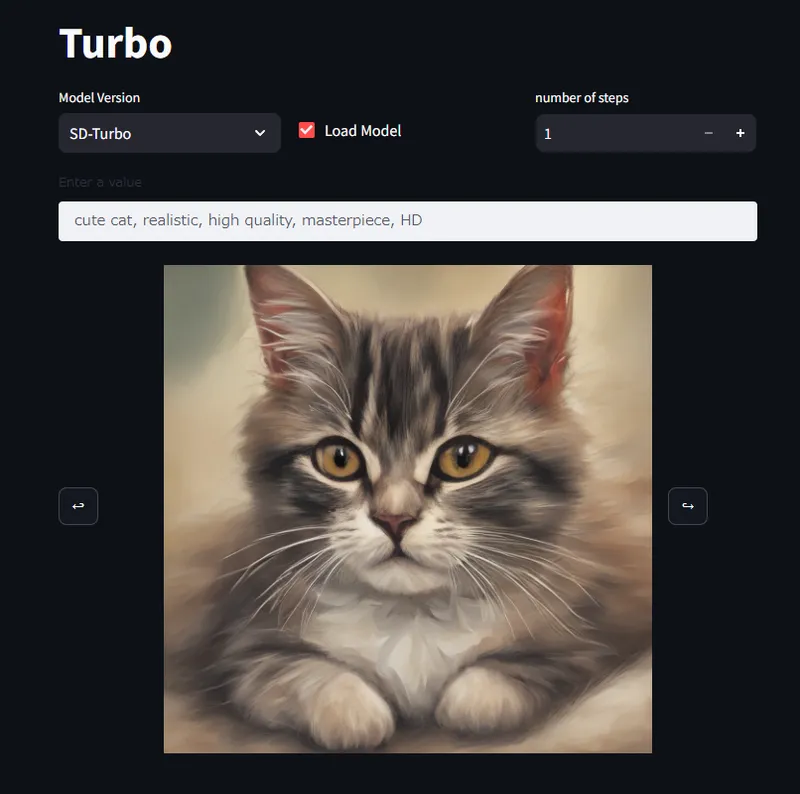
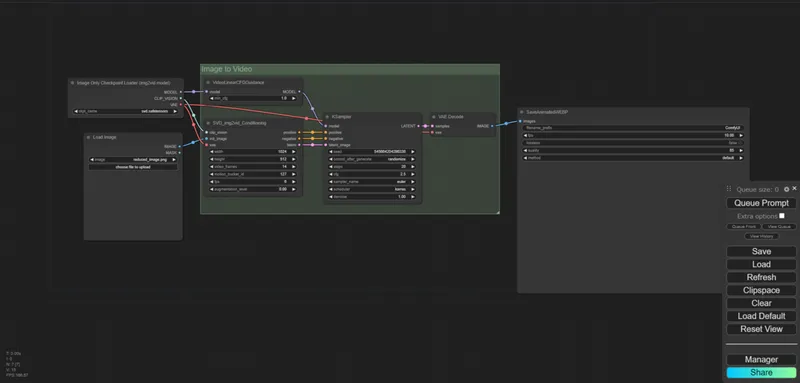
【Stable Diffusion】ComfyUIを使って画像生成AIで遊んでみよう【導入編】
Series: comfyui-image-guide
この記事では、Stable Diffusionをスムーズに導入するための具体的な手順を紹介します。Windowsでのスタンドアロン版、comfy-cliを使った方法、そしてManual Installの3つの方法について、詳細な手順をわかりやすく解説しています。初心者でも安心してインストールできるガイドです。