シリーズ

AI & Creativity
2分で読了
【Stable Diffusion】ComfyUIを使って画像生成AIで遊んでみよう【Outpaint編】
Series: comfyui-image-guide
この記事では、ComfyUIを使って、Stable DiffusionのOutpaintを行う手順を紹介します。Outpaintを使用することで、自分で描かずとも、画像の外側に新しい内容を追加することができます。
AI & Creativity
画像・動画・音楽生成 AI の使い方、ComfyUI や Stable Diffusion の実験ノート
この記事では、ComfyUIを使って、Stable DiffusionのOutpaintを行う手順を紹介します。Outpaintを使用することで、自分で描かずとも、画像の外側に新しい内容を追加することができます。
画像生成AI「Stable Diffusion」をさらに強力にするIPAdapterの解説。画像プロンプトで画風や構図をコントロールする仕組みと、ComfyUIへのCustom Node導入・モデル配置・ワークフロー構築手順、画像生成デモ(顔入れ替えなど)を初心者向けに紹介します。
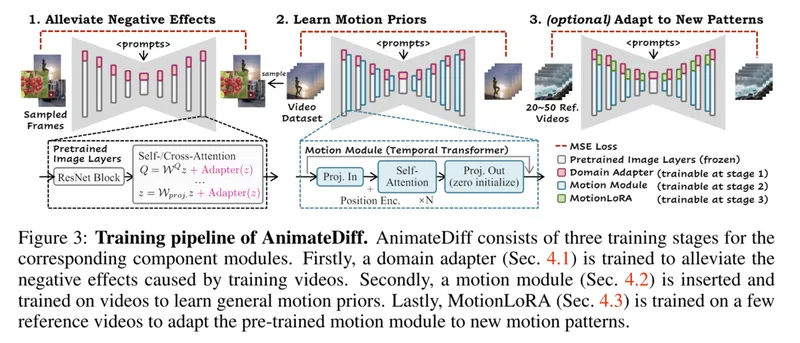
AnimateDiffは、Stable Diffusionモデルを拡張して動画生成を可能にする新技術です。その特徴であるDomain AdapterやMotion Moduleについて、そして高品質なアニメーション生成の仕組みを簡単に解説します。
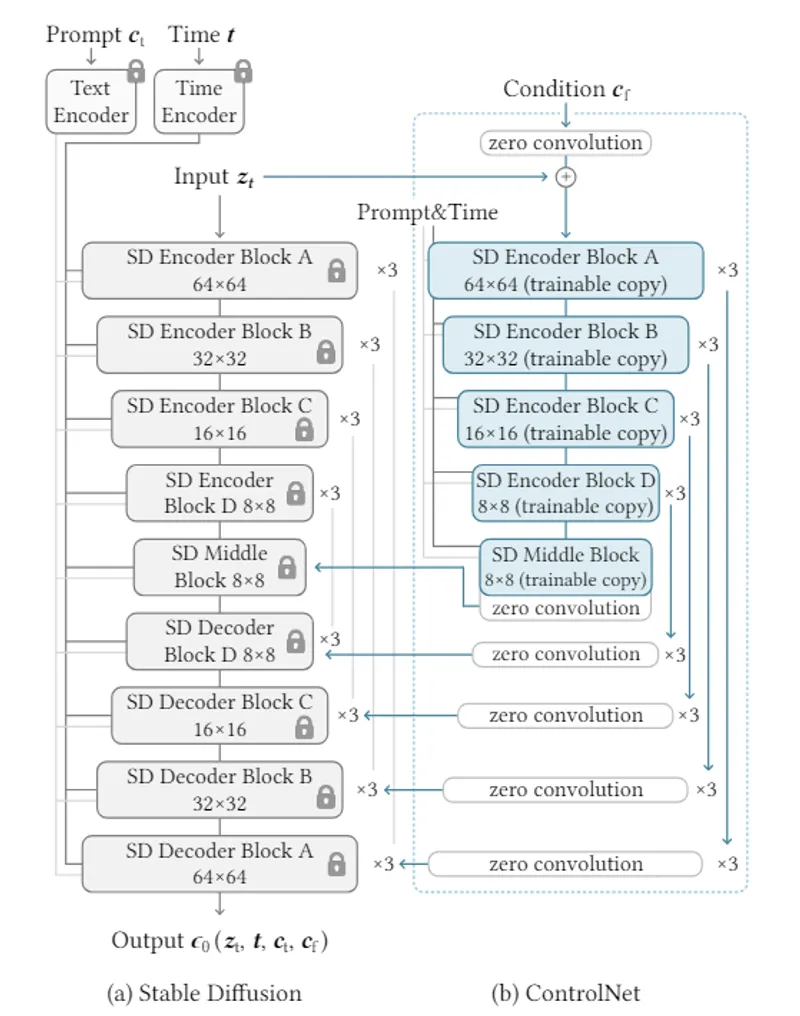
画像生成AI「Stable Diffusion」の拡張機能「ControlNet」の基礎を解説。人物の姿勢などの空間的な条件付けを学習・制御する仕組みや、Zero Convolutionを用いたノイズ抑制のアーキテクチャについて、論文の図解を交えて紹介します。
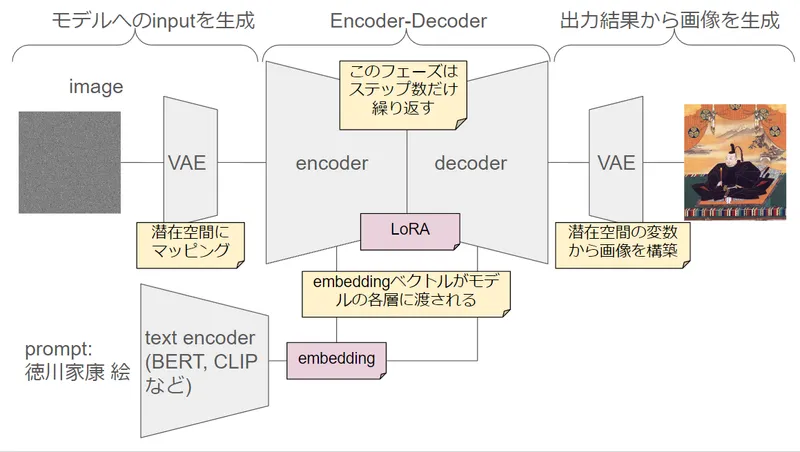
Textual Inversionは、プロンプトの言語ベクトルを通じてStable Diffusionの出力を制御する手法です。LoRAとの違いを比較しながら、初心者にも理解しやすい形でその仕組みと応用方法を紹介します。
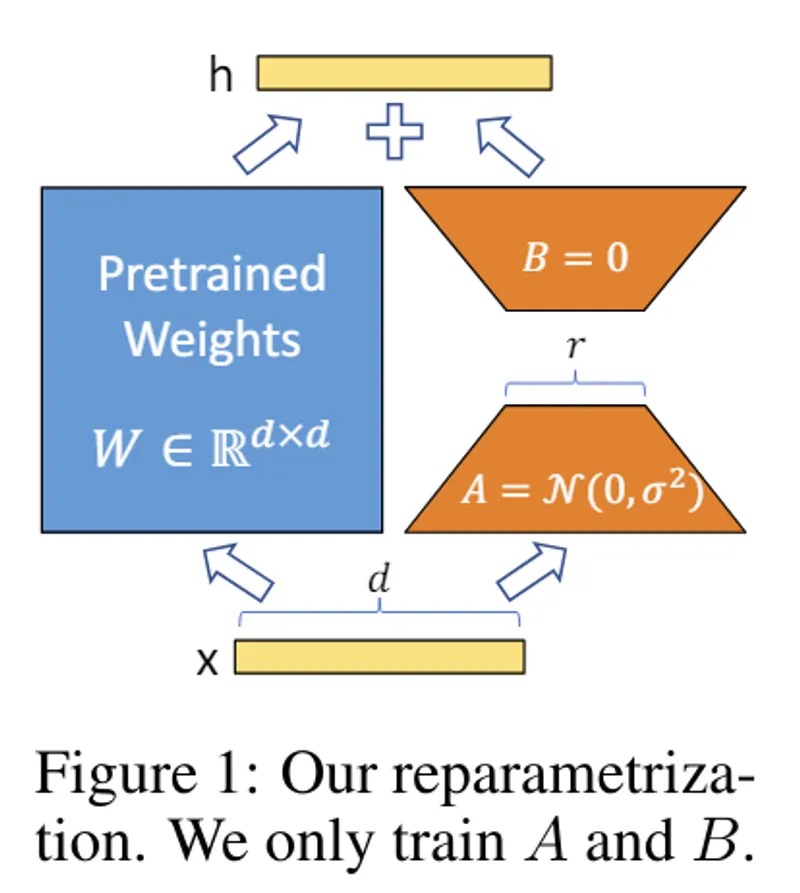
機械学習や画像生成AIで注目を集める「LoRA」の仕組みを初心者向けに解説。巨大なTransformerモデルの重みを固定し、低ランク行列を追加することで計算コストやメモリを使わずに効率的にファインチューニングする手法やメリットを紹介します。
ComfyUIを使ってStable Diffusionでembeddingを使用する方法を紹介します。好きなembeddingを使用した実例とその効果の違いを画像で比較し、より良い生成結果を得るためのポイントも解説します。
この記事では、Stable Diffusionの画像生成モデルの仕組みを解説します。拡散モデルの基本概念からLatent Diffusion Models(LDM)の詳細まで、理論的背景と具体的なプロセスを説明。なんとなくで使ってるその技術、どうやって動いてるか知りたくないですか?
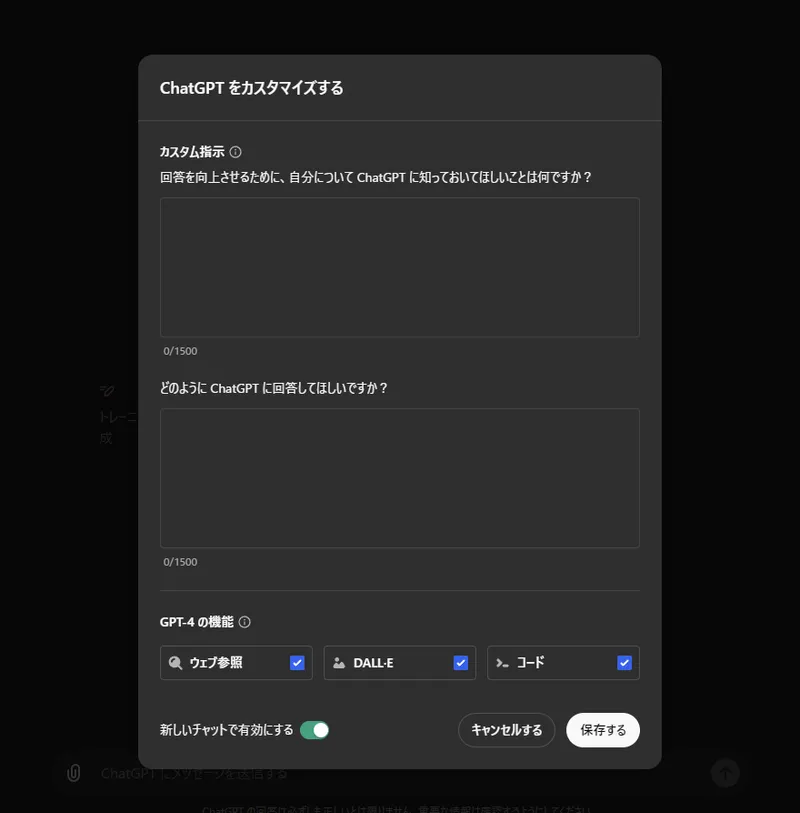
この記事では、ChatGPTのCustom Instructions機能を活用し、応答の正確性向上や特定のコマンドの覚えさせ方を解説します。各種カスタマイズ例を紹介し、日常的なやり取りをより効率的にするためのヒントを提供。初心者にもわかりやすく、ステップバイステップで説明しています。
この記事では、Stable Diffusionを拡張したAnimateDiffを用いて動画を生成する方法を解説します。モデルの概要、学習手法、各種モジュールの役割について詳述。さらに、ComfyUIの導入と具体的なワークフローの設定手順を紹介し、実際に動画を生成するまでのステップを丁寧に説明しています。
画像生成AIで人物のポーズや構図を制御できる拡張技術「ControlNet」の基本的な使い方を解説。抽出データ(姿勢情報・線画など)を入力とする仕組みから、「ComfyUI」での具体的なワークフロー構築・生成手順までを初心者向けに紹介します。
画像生成AI「Stable Diffusion」で生成した画像を高解像度化(アップスケール)し、細部のディテールを鮮明に描き込む手法「Hires.fix」の仕組みとメリットを解説。GUI環境「ComfyUI」を使って、Upscale Latentノードを組み込んだ具体的なワークフロー作成手順を紹介します。