This is a collection of explanatory articles on papers around Stable Diffusion.
Image Generation
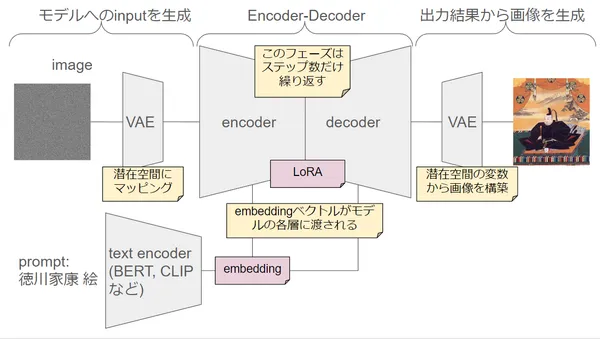
Stable Diffusion
Everyone’s favorite Stable Diffusion model. It is a model that combines Text Encoder, UNet, and VAE.

>-
Stable Diffusion 3
An update of the Stable Diffusion model to the latest technology. It changes to a Transformers-based model called MMDiT instead of UNet, and includes some tweaks such as optimizing the noise schedule and increasing the TextEncoder to three.
>-
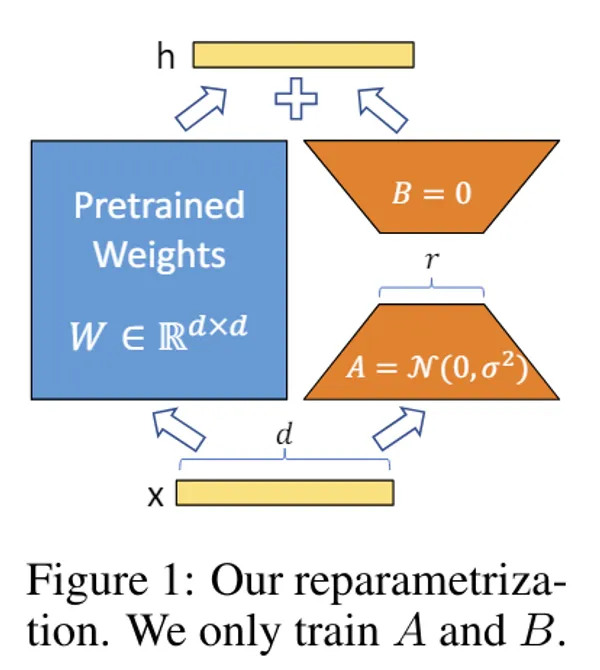
LoRA
Everyone’s favorite LoRA. It can be said to be an expansion part of the model, and additional learning of the model can be performed just by increasing the parameters a little. (Originally proposed for language models)
>-
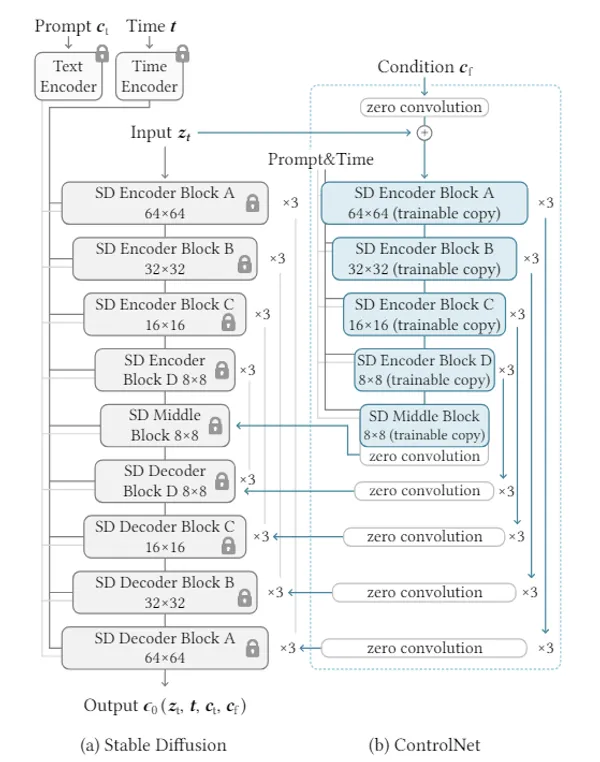
ControlNet
ControlNet is a model extension for controlling the pose of the person in the image. UNet is doubled and one is made to learn posture data.
>-
Textual Inversion
A method of tweaking the Text Encoder instead of UNet. Since the outside of the main body, UNet, is tweaked, the effect is relatively weak, but there are advantages such as no need to increase parameters and learning is easier than tweaking UNet.
>-
IPAdapter
A method of preparing an Image Encoder in parallel with the Text Encoder so that it can receive image prompts.
>-
Video Generation
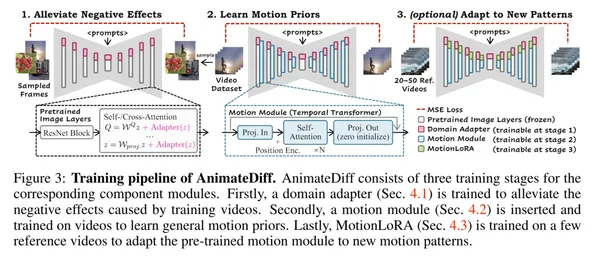
AnimateDiff
A model that adds layers to Stable Diffusion so that it can learn the time axis.
>-
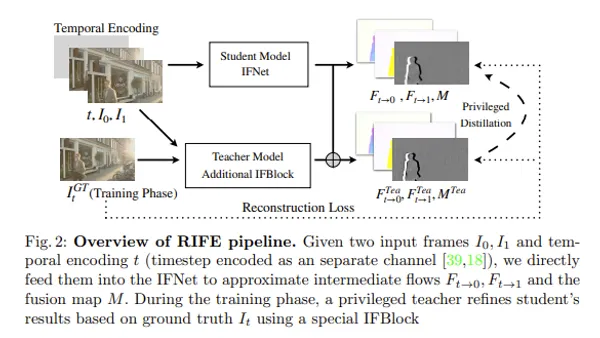
RIFE
Technology to generate intermediate frames and improve video frame rates.
>-
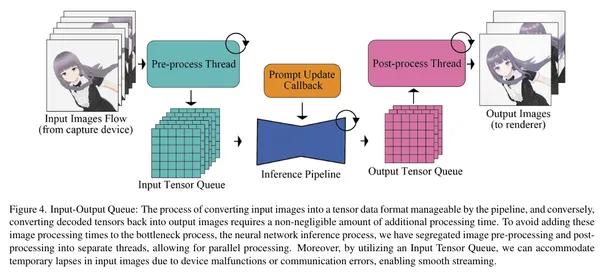
Stream Diffusion
A model that enables ultra-high-speed image generation by introducing pipeline processing and other speed-up techniques. Maximum 91.07fps with RTX 4090.
>-