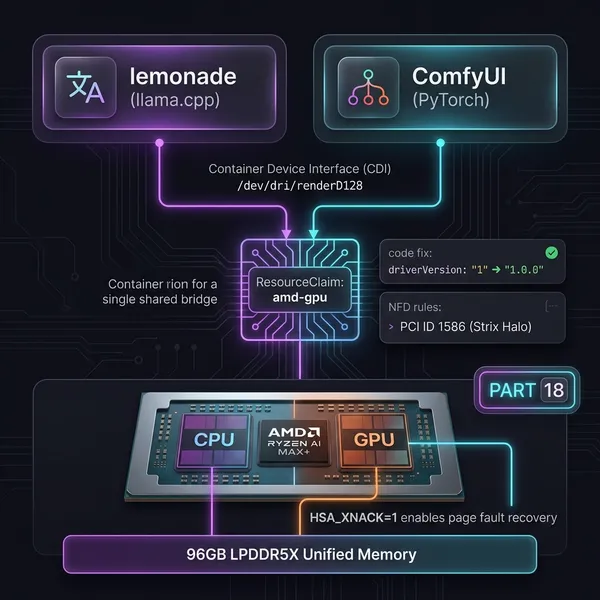
In the previous post, I fixed the MES firmware bug and got lemonade running. But after using it for a while, a different problem surfaced. That’s what this post is about.
What Happened
lemonade crashed mid-inference. Processes dying from OOM or during model loading is pretty common with inference servers, so that part wasn’t surprising. What happened next was.
The Pod restarted, but the GPU was unusable. The VM’s dmesg showed it stalling with this error:
[ 40.4] amdgpu: PSP tmr init failed!Restarting the VM didn’t help. Rebooting the host didn’t help. Powering off and back on (short of a full discharge) didn’t help either.
That last one was unexpected. I knew a software reset wouldn’t clear firmware state, but I didn’t expect an OS-level power cycle to leave the GPU in the same dirty state.
Why Recovery Isn’t Possible
Strix Halo is an APU, so the GPU-side PSP (Platform Security Processor) is tightly coupled with the CPU-side ASP (AMD Security Processor / CCP). When lemonade exits without cleanly releasing the GPU, the PSP leaves TMR (Trusted Memory Region) in a dirty state.
On the next boot, PSP tries to initialize against that dirty state, hits UNKNOWN CMD(0xFFFFFFFF) (a timeout), and fails.
In a VFIO environment, the ASP is passed through “as a VM device,” so it can’t directly access the host’s physical resources. This appears to be why PSP resets don’t work correctly across VFIO. On bare metal, the same crash happens but the Pod just restarts and recovers — so this was a VFIO-specific problem.
Most of this is pieced together from Reddit threads, so take it with a grain of salt — but it does seem to fit the symptoms.
What I Tried
FLR (Function Level Reset)
echo 1 > /sys/bus/pci/devices/0000:c5:00.0/resetNo effect. FLR doesn’t clear PSP firmware state.
vendor-reset module
The usual fix for AMD GPU reset issues, but it fails to build on kernel 7.x. Strix Halo isn’t supported anyway.
Neither approach worked, and I ran out of options.
Switching to Bare Metal
The obvious conclusion: skip Incus VM entirely, install Ubuntu directly on the host, and run k3s there.
Not being able to match the architecture of the other nodes was a minor annoyance, but a setup where every GPU crash leaves you reaching for the power cable isn’t operationally viable.
Final Configuration
- Bare-metal Ubuntu 26.04 (no Incus)
- Kernel built-in amdgpu + ROCm 7.2.3
- k3s agent installed directly
- AMD GPU Operator + DRA driver for Kubernetes GPU access
Now when lemonade crashes, the Pod restarts and everything just works again. The stability compared to the VFIO setup isn’t even close.
Takeaway
VFIO passthrough works well when things are running smoothly, but on an APU like Strix Halo, once the GPU enters a dirty state there’s no software path back. For an inference server that you can’t fully protect from crashes, a VFIO-based setup isn’t sustainable.
Bare metal felt like admitting defeat at first, but stable beats clever.
Hope this helps anyone hitting the same wall.