AI & Creativity
3分で読了
ComfyUIを使って落書きからリアルタイムで画像生成してみる
ComfyUIとLCM-LoRAを活用し、ローカル環境で落書きからAI画像をリアルタイム生成する方法を解説!必要なカスタムノードの導入からワークフローの設定、Auto Queue機能を使った動的な画像生成プロセスまで詳しく紹介します。akuma.aiのような体験を自分のPCで再現しましょう。
AI & Creativity
画像・動画・音楽生成 AI の使い方、ComfyUI や Stable Diffusion の実験ノート
ComfyUIとLCM-LoRAを活用し、ローカル環境で落書きからAI画像をリアルタイム生成する方法を解説!必要なカスタムノードの導入からワークフローの設定、Auto Queue機能を使った動的な画像生成プロセスまで詳しく紹介します。akuma.aiのような体験を自分のPCで再現しましょう。
無料のペイントソフト Krita と Stable Diffusion 拡張(krita-ai-diffusion)を組み合わせ、落書きからAI画像をリアルタイム生成する手順を解説!プラグインの導入からサーバー設定、Live Preview機能を使った直感的な画像生成方法まで初心者向けにガイドします。
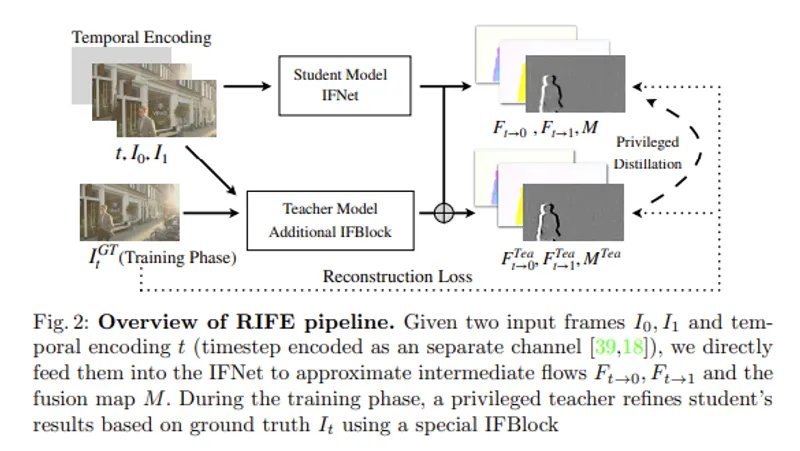
ディープラーニングを用いた動画のフレーム補間技術「RIFE」のアーキテクチャを解説。高精度のオプティカルフロー推定を実現する「IFNet」の仕組みや、モデルサイズを抑えつつ精度を高める「特権蒸留(Privileged Distillation)」の手法について、論文の内容をもとに分かりやすく紹介します。
画像生成AI環境「ComfyUI」を使って動画から動画を生成する「Vid2Vid」のやり方を解説。AnimateDiffやControlNet等を組み合わせ、指定した顔の特徴を維持したまま高精度に動画変換する手順や生成結果を紹介します。
この記事では、ComfyUIを使ってStable Diffusion 3で画像を生成する方法をステップバイステップで解説します。ComfyUIの導入、必要なモデルのダウンロードと配置、ワークフローのインポート方法を詳しく説明し、実際に生成した画像の評価とともに全体的な使用感をお伝えします。
Stable Diffusion 3は、CLIPとT5を組み合わせた新しいText Encoderや、DiTアーキテクチャの導入で大幅に進化しました。新しいノイズスケジューラーにより、生成性能が向上し、txt2imgで最先端モデルを超える性能を実現。簡単に論文の内容を説明します。
StabilityMatrixを利用してComfyUIをインストールし、設定する手順を詳しく解説。モデルの管理や実際の画像生成プロセスについても触れ、実際に試してみた感想とともに、利点と欠点を紹介します。
Stable Audio Openが無償公開され、ローカル環境で高品質なAI楽曲生成が可能になりました。この記事では、Stability AIのリポジトリを使用した公式デモの構築手順や、実際に生成した音源サンプルを紹介します。
Stream Diffusionはリアルタイムで高品質な画像生成を可能にする技術です。この記事ではStream Diffusionがどのようにリアルタイムの画像生成を可能にしているのかを簡単に説明します。
ComfyUIでESRGANを使用して、画像生成AIの出力を高画質化・アップスケールする手順を解説します。Hires.fixとの違いや、おすすめのモデル(4x-Ultrasharp等)の導入方法についてエンジニア目線で深掘りします。
IPAdapterは、既存のStable Diffusionモデルに画像プロンプト機能を追加し、計算コストを抑えながらも画像のスタイルを維持した画像生成を実現します。この記事では、そのアーキテクチャやメリット、評価結果について簡潔に解説します。
ComfyUIを使ったStableDiffusionによるInpaint技術の手順を詳しく解説。画像の特定部分をマスクし、新たな要素を追加する方法をステップバイステップで説明します。生成結果も掲載しています。