I set up LiteLLM Proxy to put local LLMs and ChatGPT subscription models behind a single endpoint. Here’s how it works.
The interesting part is how ChatGPT connects — no API key needed, just a ChatGPT subscription. gpt-5.5, gpt-5.4-mini, all accessible via subscription. Better cost predictability than pay-per-token API billing.
Connecting ChatGPT via Subscription
LiteLLM has a chatgpt provider that authenticates via OAuth device code flow. Authenticate once in a browser, and the token persists on the host. Pod restarts don’t require re-authentication. Since it’s a refresh token, re-authentication may be needed after an extended period.
chatgpt: models: - name: "gpt-5.5" - name: "gpt-5.4" - name: "gpt-5.4-mini" - name: "gpt-5.3-codex" tokenHostPath: /var/lib/k8s/litellm/chatgpttokenHostPath persists the auth token via hostPath.
Local LLM Side
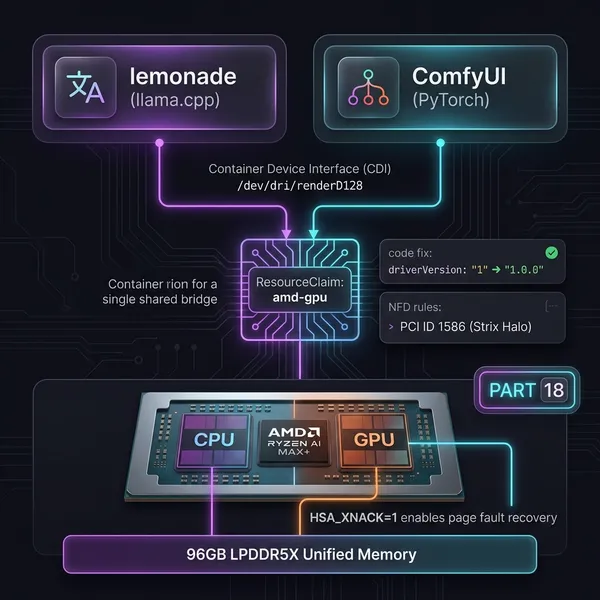
Local models run on Lemonade, an AMD ROCm-based llama.cpp wrapper with an OpenAI-compatible endpoint. The hardware here is a Strix Halo (Ryzen AI MAX+) where GPU and CPU share 128GB of memory.
Currently running 3 models:
Gemma-4-E4B-it-GGUF → 4B, lightweight and fastQwen3.6-35B-A3B-GGUF → MoE, ~3.5B effective parametersgemma-4-26B-A4B-it-uncensored → custom, 26B MoELemonade handles multiple models with LRU swapping. 128GB of shared memory means VRAM pressure is rarely an issue.
One Endpoint for Everything
Point anything at inference.homelab.otama-playground.com and both local models and ChatGPT are available. Switching is just a matter of changing the model name in the request.
Gemma-4-E4B-it-GGUF-nothink → local, thinking mode disabledchatgpt/gpt-5.5 → ChatGPT subscriptionThe -nothink alias disables the thinking chain. Gemma-4 and Qwen3 models generate reasoning steps by default, which is overkill for lightweight tasks like commit message generation. The alias runs the same model without it.
When a local model tries to call a web search tool, requests are routed to a self-hosted SearXNG instance.
Thinking About Adding opencode
opencode speaks OpenAI-compatible APIs, so it can connect to LiteLLM too. opencode Go apparently offers API key access via subscription, which — like ChatGPT — makes cost predictable, which is nice.
The current thinking on model tiers: heavy tasks like advisor work, design, and review go to gpt-5.5; everything else goes to local LLMs. The gap is that there’s no Sonnet-class model in between. Adding DeepSeek v4 Pro via opencode might fill that middle tier nicely — still evaluating.
Summary
LiteLLM as a proxy layer means local LLMs and ChatGPT subscription models are accessible from a single endpoint. Clients just change the model name to switch between them.
Connecting ChatGPT via subscription turned out to be more useful than expected — GPT-5-class models without per-token billing concerns. Combining nothink variants and SearXNG routing means lightweight tasks run at nearly zero cost. The opencode integration is still being figured out, but if it works out there’ll be another post.
Since ComfyUI is also running locally, the eventual goal is to get /image/generation working through the same LiteLLM endpoint too.