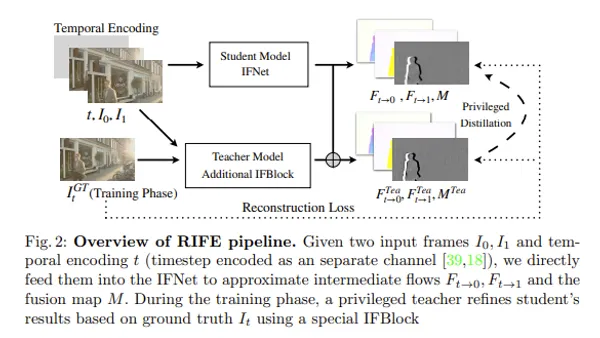
IPAdapter is a new adapter providing lightweight and high-performance image prompt function to existing txt2img diffusion models. Compared to conventional adapter models, IPAdapter demonstrates excellent performance while suppressing calculation cost, improving quality of image generation greatly. In this article, I explain briefly about architecture of IPAdapter, its merit, and evaluation result.
Note: Please understand this is a note to grasp overview and does not treat mathematical parts.
What is IPAdapter

Recent years have witnessed the strong power of large text-to-image diffusion models for the impressive generative capability to create high-fidelity images. However, it is very tricky to generate desired images using only text prompt as it often involves complex prompt engineering. An alternative to text prompt is image prompt, as the saying goes: "an image is worth a thousand words". Although existing methods of direct fine-tuning from pretrained models are effective, they require large computing resources and are not compatible with other base models, text prompt, and structural controls. In this paper, we present IP-Adapter, an effective and lightweight adapter to achieve image prompt capability for the pretrained text-to-image diffusion models. The key design of our IP-Adapter is decoupled cross-attention mechanism that separates cross-attention layers for text features and image features. Despite the simplicity of our method, an IP-Adapter with only 22M parameters can achieve comparable or even better performance to a fully fine-tuned image prompt model. As we freeze the pretrained diffusion model, the proposed IP-Adapter can be generalized not only to other custom models fine-tuned from the same base model, but also to controllable generation using existing controllable tools. With the benefit of the decoupled cross-attention strategy, the image prompt can also work well with the text prompt to achieve multimodal image generation. The project page is available at \url{https://ip-adapter.github.io}.

Overview of IPAdapter
IPAdapter is a lightweight adapter enabling image generation using image prompt for pre-trained txt2img diffusion model.
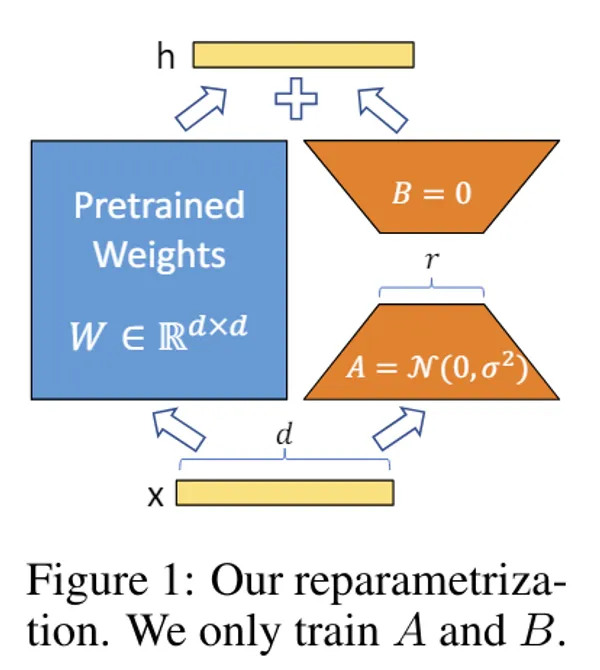
※What is Adapter
Adapter in machine learning is a method used when fine-tuning large-scale pre-trained model. Adapter freezes parameters of existing model and learns small amount of additional parameters to correspond to new task or condition. By this, while reducing calculation cost largely, it is possible to add new function while maintaining performance of original model.
Architecture of IP Adapter
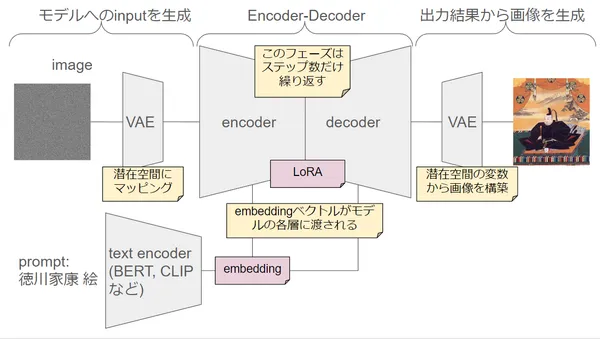
IP Adapter adds following two layers to Stable Diffusion model to encode feature of image and input to model.
- Image Encoder
- Layer extracting image feature from image prompt.
- Add only linear combination layer for fine-tuning between models behind encoder and learn only there.
- Encoder uses learned one. (ViT is used in paper.)
- Decoupled Cross-Attention
- Layer incorporating extracted image feature into pre-trained base model.
- Original model has only Cross Attention for text prompt, but separate from this, Cross Attention for image prompt is added.
Architecture after addition is below, and red part is added layer. Add Encoder for image in parallel position with Text Encoder, and join this to UNet side with Cross Attention prepared newly for IP Adapter.
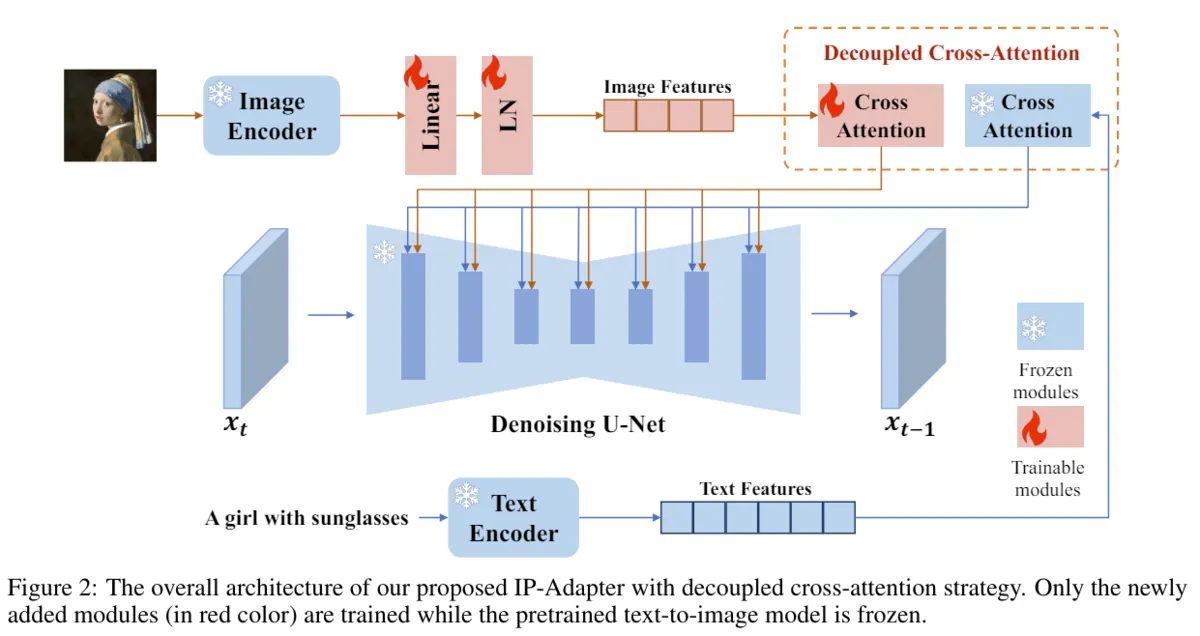
What it is doing is just making image into language vector and inputting to UNet via Cross Attention, so I think it is almost same as Text Encoder. As novelty, by making Cross Attention layer separate, prompts of text and image do not compete, features of both are utilized independently, and it is inferred that quality improved.
Merit of IP Adapter
- Can learn model lightly, and high performance
- It seems performance equal to or more than fine-tuning comes out without fine-tuning entire model. It claims learning parameter of IP Adapter itself is least among competing researches and cost is low.
- Versatility
- Compatible with various learned base models, and existing tools like ControlNet, T2I-Adapter.
Basically merit is same as LoRA, and I understood that since it is working with mechanism independent from UNet (same position as TextEncoder), it works well even in combination with other tools (ControlNet, LoRA).
Evaluation Result
Result shows that in all models, it is generated as different image while maintaining style.

Summary
IPAdapter is a technology realizing high performance image generation at low cost, and wide application is expected. Through architecture and evaluation result introduced in this article, I think you could understand its usefulness and potential possibility.
Since how to use in ComfyUI is explained in article below, please try.

>-
Since papers read around Stable Diffusion are summarized in following article, please utilize if interested.
Stable Diffusion関連の論文解説記事のリンク集。画像生成・動画生成の基礎モデルから応用技術まで論文ベースで解説。