Series

Infrastructure & Engineering
6 min read
Autonomous k8s Debugging and Tuning with Claude Code Skills
Series: home-kubernetes-journal
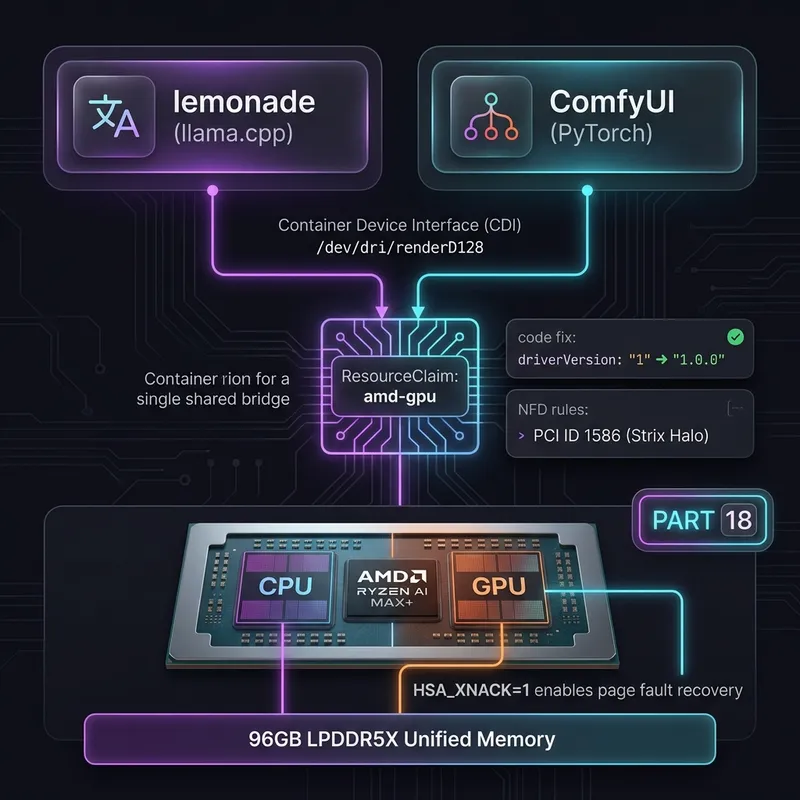
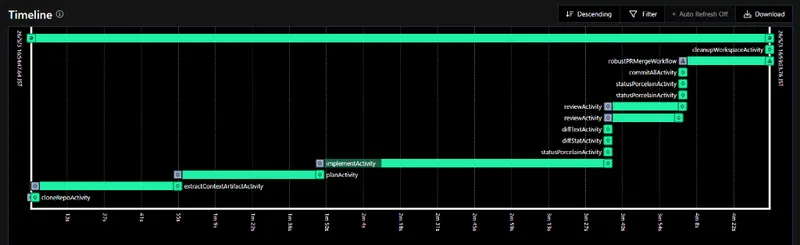
Using Claude Code skills to automate k3s diagnosis and repair on my homelab, plus LLM inference tuning that pushed Hermes TPS from 21 t/s to 32+ t/s.