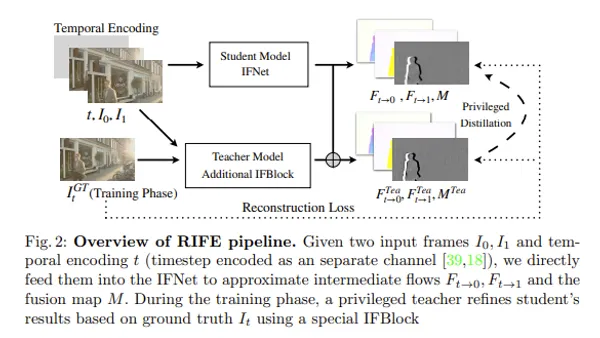
Although playing around various things until now, I haven’t learned about Stable Diffusion model itself, so I will insert phase to understand before playing other various things.
Stable Diffusion is a model extended based on Latent Diffusion Model (LDM) which is a kind of diffusion model. Therefore to know mechanism of Stable Diffusion model, first you need to know about diffusion model and LDM. In this article, after briefly explaining diffusion model and LDM, I will enter explanation of Stable Diffusion itself.
What is Diffusion Model
First understand about diffusion model which is important concept in Stable Diffusion.

We present high quality image synthesis results using diffusion probabilistic models, a class of latent variable models inspired by considerations from nonequilibrium thermodynamics. Our best results are obtained by training on a weighted variational bound designed according to a novel connection between diffusion probabilistic models and denoising score matching with Langevin dynamics, and our models naturally admit a progressive lossy decompression scheme that can be interpreted as a generalization of autoregressive decoding. On the unconditional CIFAR10 dataset, we obtain an Inception score of 9.46 and a state-of-the-art FID score of 3.17. On 256x256 LSUN, we obtain sample quality similar to ProgressiveGAN. Our implementation is available at https://github.com/hojonathanho/diffusion

Diffusion model is a model that adds “noise” gradually to original data (e.g. image or audio), uses data that became almost random number state as training data, and learns method to reconstruct original data by removing noise from there.
Basic Concept of Diffusion Model
- Diffusion Process
- Process where data point (image etc.) is converted to random noise gradually.
- This is performed only in learning process.
- Reverse Diffusion Process:
- Reconstruct original data gradually from noise.
- Generative model learns this reverse diffusion process, becoming able to generate plausible data even from random noise.
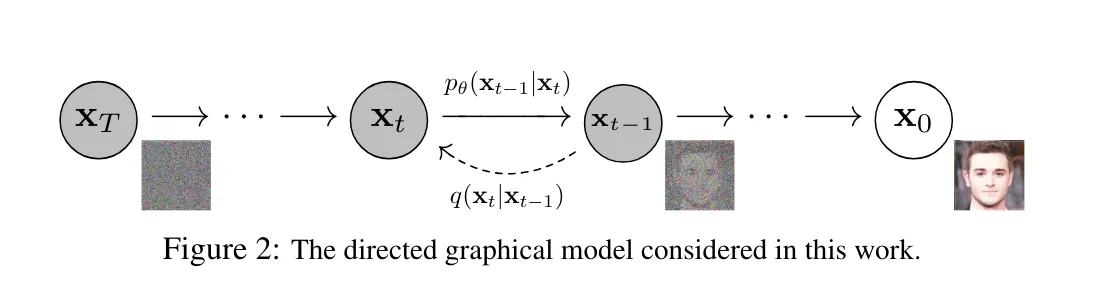
Image below is pulled from paper of diffusion model. This image shows process of reverse diffusion process, and same processing is performed in Stable Diffusion.
Mechanism
- Forward Diffusion Process
- Gradually add Gaussian noise to original data (e.g. image), finally making it pure noise.
- Starting from original data ( ), add noise at each step ( ), generating ( ).
- is noise schedule, is Gaussian noise
- Reverse Diffusion Process:
- Reconstruct original data from noise data generated in Forward Diffusion Process.
- Model learns conditional probability distribution going backward from step ( ) to step ( ).
Learning Method
- Train model using noise data generated in Forward Diffusion Process.
- Aiming to approximate probability distribution of Reverse Diffusion Process accurately, loss function for that is used.
What is Latent Diffusion Model
Next explaining Latent Diffusion Models (LDM) which became base of Stable Diffusion model.
By decomposing the image formation process into a sequential application of denoising autoencoders, diffusion models (DMs) achieve state-of-the-art synthesis results on image data and beyond. Additionally, their formulation allows for a guiding mechanism to control the image generation process without retraining. However, since these models typically operate directly in pixel space, optimization of powerful DMs often consumes hundreds of GPU days and inference is expensive due to sequential evaluations. To enable DM training on limited computational resources while retaining their quality and flexibility, we apply them in the latent space of powerful pretrained autoencoders. In contrast to previous work, training diffusion models on such a representation allows for the first time to reach a near-optimal point between complexity reduction and detail preservation, greatly boosting visual fidelity. By introducing cross-attention layers into the model architecture, we turn diffusion models into powerful and flexible generators for general conditioning inputs such as text or bounding boxes and high-resolution synthesis becomes possible in a convolutional manner. Our latent diffusion models (LDMs) achieve a new state of the art for image inpainting and highly competitive performance on various tasks, including unconditional image generation, semantic scene synthesis, and super-resolution, while significantly reducing computational requirements compared to pixel-based DMs. Code is available at https://github.com/CompVis/latent-diffusion .
Latent Diffusion Model is a kind of diffusion model performing diffusion process in low-dimensional latent space (Latent Space). Since this method requires fewer model parameters compared to conventional method operating in high-dimensional image space, it can reduce calculation cost and memory usage significantly, leading to efficiency of learning and speedup of image generation.
Basic Concept of LDM
- Latent Space
- Perform diffusion process after mapping complex structure of data to low-dimensional latent space.
- Diffusion process in latent space with fewer parameters than image space improves calculation efficiency.
Mechanism
- Encoder
- Latent Diffusion Process
- Add noise to latent variable ( ) same as normal diffusion process.
- Forward Diffusion Process (Same as diffusion model)
- is noise schedule, is Gaussian noise
- Reverse Diffusion Process
- Reconstruct original latent variable from noise data in latent space (Same as diffusion model).
- Model learns conditional probability distribution going backward from step ( ) to step ( )
- Here, is parameter of model.
- Decoder
- Generate original high-dimensional data from reconstructed latent variable ( ).
- Using Decoder ( ), obtain reconstructed data ( ) from latent variable ( )
Learning Method
- Training of Forward Diffusion Process and Reverse Process
- Using noise data generated in Forward Diffusion Process, learn probability distribution of Reverse Diffusion Process (Same as diffusion model).
- Goal of learning is to approximate probability distribution of Reverse Diffusion Process accurately. (This is also same as diffusion model)
About Stable Diffusion
Stable Diffusion is implementation of image generation model based on LDM, and what added techniques to LDM to make learning efficient and image generation high precision is Stable Diffusion.
Techniques Used etc.
For example techniques like below are used.
- Variational Autoencoder (VAE)
- Stable Diffusion uses Variational Autoencoder (VAE) to learn representation of latent space. Since VAE brings latent representation of data closer to normal distribution, it provides stable latent space.
- Cross Attention Mechanism
- By introducing Cross Attention Mechanism, effectively integrate information of latent space and information of original high-dimensional data.
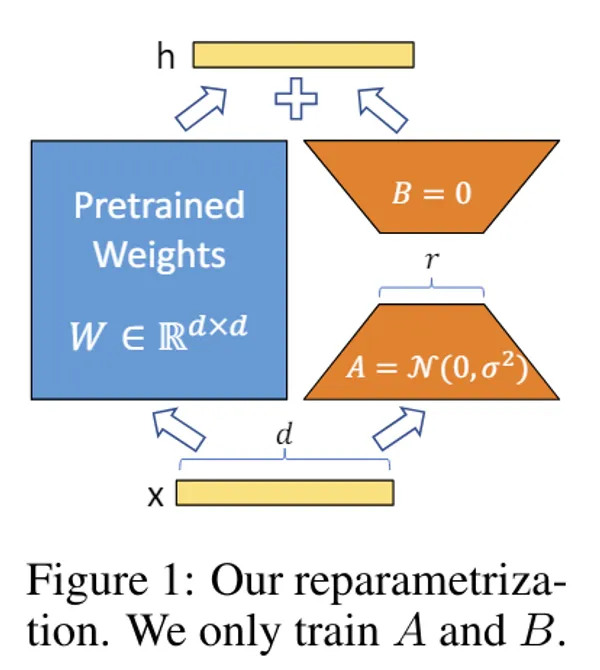
- Adapter
- There is method to insert small learnable module called Adapter into model and fine-tune, this is efficient in memory and time, enabling effective customization without requiring large-scale calculation resources
- LoRA etc. is this. (Depending on how you say, AnimateDiff too)
- Speedup
- By incorporating technologies like Latent Consistency Models (LCM), Stable Diffusion can realize high quality image generation with minimum inference steps
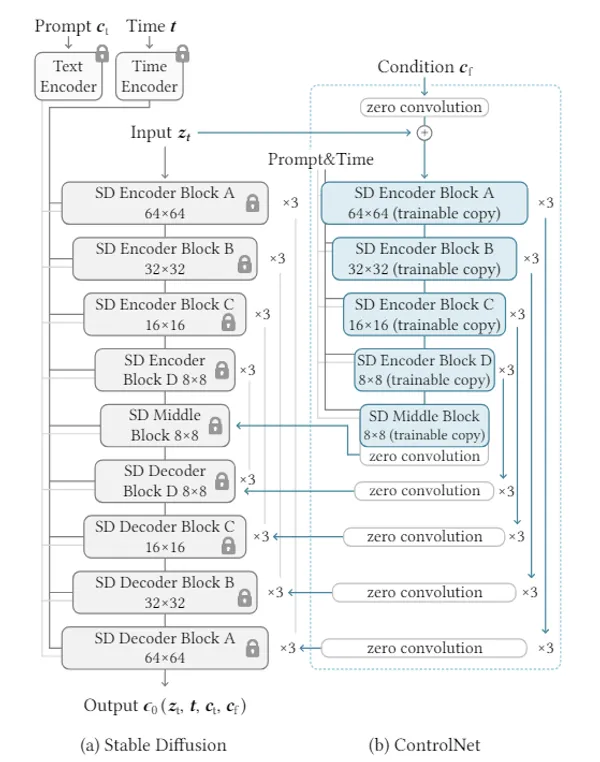
Architecture of Model
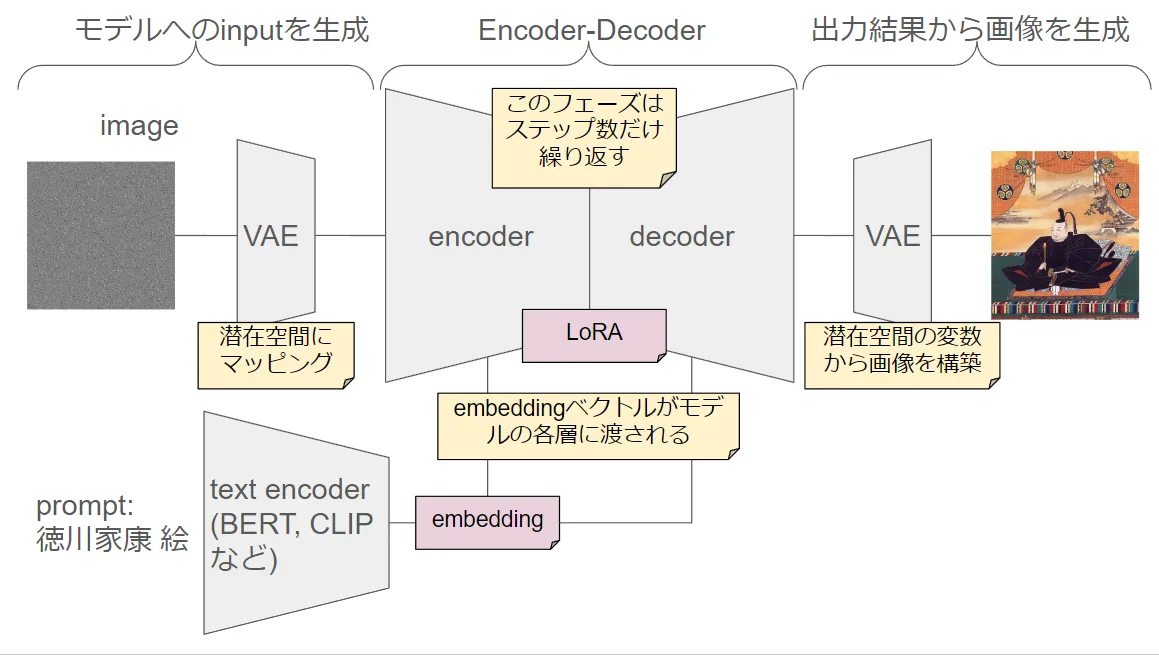
Conclusion
Since I felt I understood to extent of touching, I stop here. For those who felt explanation was too fluffy and didn’t understand much, link to paper is also pasted in article so please read from there.
If you want to try generation actually, you can try easily if you install ComfyUI. Since installation steps are introduced in following article, please read.

>-
Since papers read around Stable Diffusion are summarized in following article, please utilize if interested.
Stable Diffusion関連の論文解説記事のリンク集。画像生成・動画生成の基礎モデルから応用技術まで論文ベースで解説。