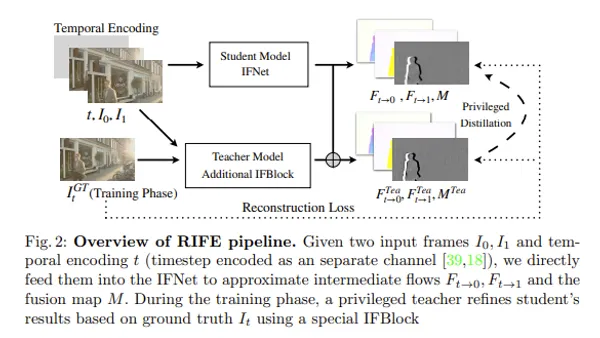
ControlNet is a revolutionary technology extending existing Stable Diffusion models and enabling learning of spatial conditioning such as person’s posture. I will explain with figures what kind of method realizes this.
About ControlNet

We present ControlNet, a neural network architecture to add spatial conditioning controls to large, pretrained text-to-image diffusion models. ControlNet locks the production-ready large diffusion models, and reuses their deep and robust encoding layers pretrained with billions of images as a strong backbone to learn a diverse set of conditional controls. The neural architecture is connected with "zero convolutions" (zero-initialized convolution layers) that progressively grow the parameters from zero and ensure that no harmful noise could affect the finetuning. We test various conditioning controls, eg, edges, depth, segmentation, human pose, etc, with Stable Diffusion, using single or multiple conditions, with or without prompts. We show that the training of ControlNets is robust with small (<50k) and large (>1m) datasets. Extensive results show that ControlNet may facilitate wider applications to control image diffusion models.

Overview of ControlNet
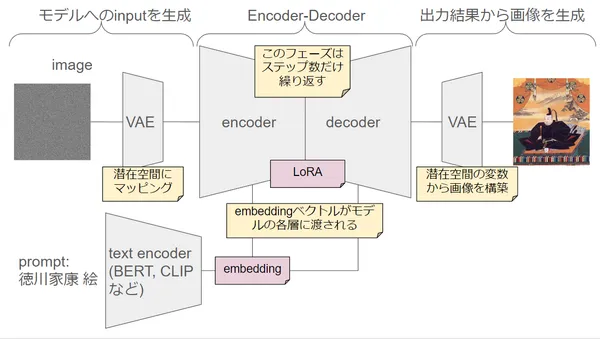
ControlNet is a method extending existing learned text2image model and enabling learning of spatial conditioning (person’s posture in this case). Add ControlNet module for learning spatial conditioning to base model, enabling learning of posture.
ControlNet Module
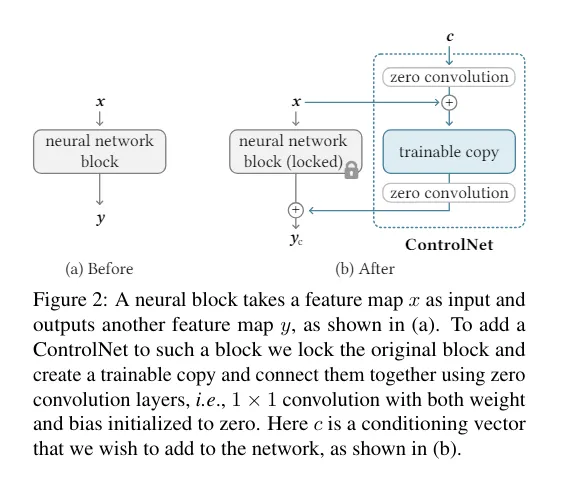
I paste architecture of ControlNet module cited from paper below (a is before ControlNet addition, b is after addition).
Fix weights of original learned model, and train only extended part to make it remember posture. By using weights held by learned model as initial value (weight) of ControlNet, learning can be done efficiently.
(Zero Convolution in figure will be explained in Appendix)
Final Architecture
I place model (architecture of base model part) cited from paper below.
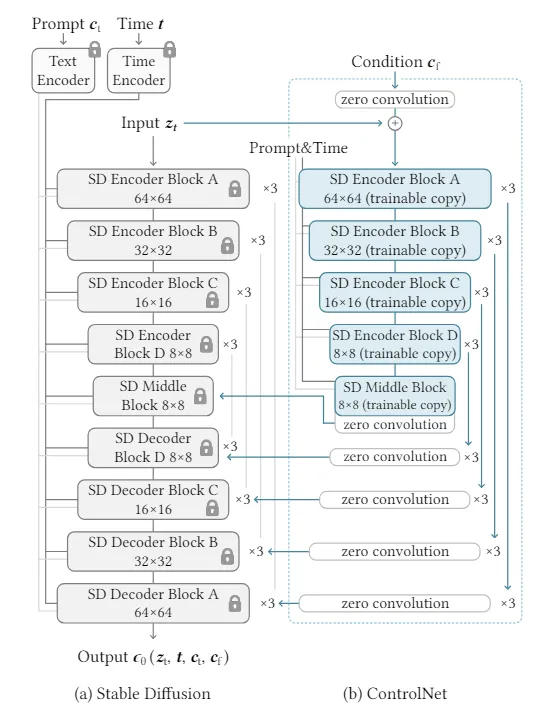
Expressing this in whole Stable Diffusion, it becomes architecture like below.
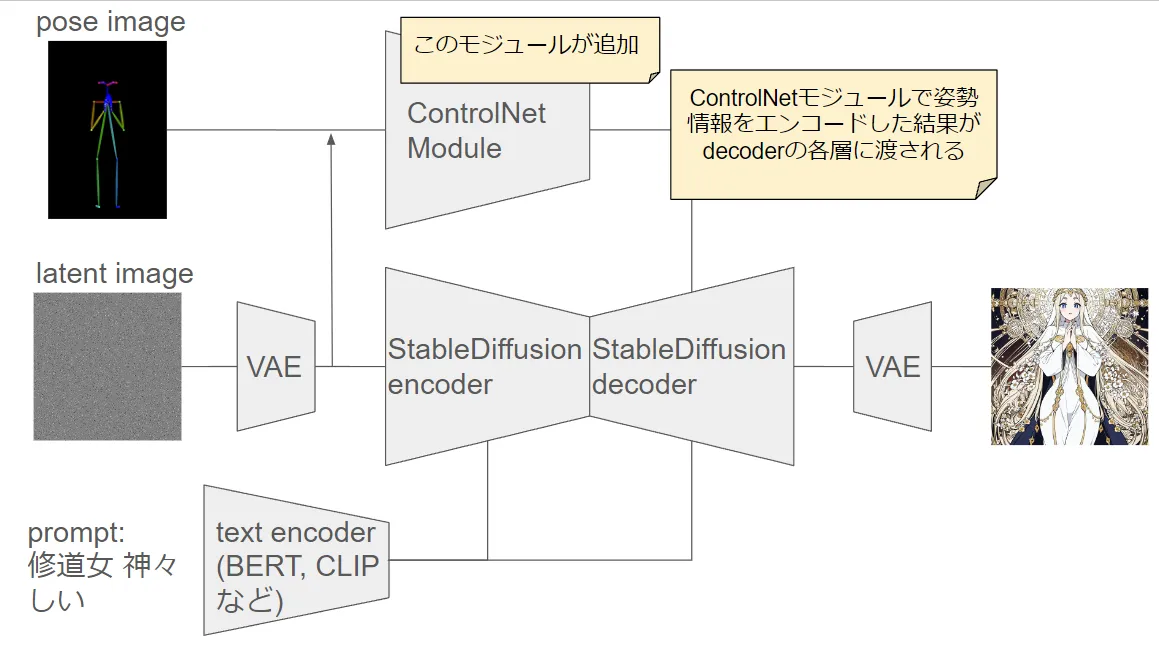
Conclusion
ControlNet brings new possibility to image generation technology by adding posture control function to Stable Diffusion model. by utilizing Zero Convolution and realizing stable learning process, higher precision image generation becomes possible. By utilizing technology introduced in this article, you will be able to build more advanced image generation model.
Since method to actually use ControlNet is explained in following article, please try if you have room.

>-
Since papers read around Stable Diffusion are summarized in following article, please utilize if interested.
Stable Diffusion関連の論文解説記事のリンク集。画像生成・動画生成の基礎モデルから応用技術まで論文ベースで解説。
Appendix
What is Zero Convolution
If initialization of convolution layer is not appropriate, parameter of model fluctuates rapidly during learning, causing irregular artifacts (undesirable pattern or defect) appearing in generated image. Such noise during learning slows down convergence of gradient, so efficiency drops.
Zero Convolution is used in ControlNet module to prevent such harmful noise. Zero Convolution suppresses noise by following two points.
- Zero Initialization
- Since parameter starts from zero, large fluctuation does not occur at initial stage of learning. This allows model to start learning stably.
- Gradually growing parameter
- By parameter growing gradually, learning process stabilizes and influence of noise can be minimized.