https://arxiv.org/abs/2106.09685
| Benefit | Description |
|---|---|
| Improved Memory Efficiency | Instead of fine-tuning the entire model, adaptation is possible with fewer parameters. Memory usage is significantly reduced, allowing operation on lightweight devices. |
| Faster Training | Training time is shortened due to the small number of parameters. Fast prototyping and experimentation are possible. |
| Flexible Adaptation | Can quickly adapt to various tasks and domains. Improvement in accuracy for custom tasks can be expected. |
| Model Reusability | Based on existing large-scale models, adaptation is possible with only additional training. Model reusability is improved, increasing cost efficiency. |
| Scalability | Flexible response to datasets ranging from small to large scale. Adaptation of large-scale models is easy. |
| Improved Performance | Adapted models often perform equal to or better than the original model. Highly practical as it is optimized for specific tasks. |
| Adaptation to Low-Resource Environments | Can be effectively used even with limited computational resources. Deployment is possible regardless of device or cloud environment. |
LoRA Methodology
As mentioned above, the points of this method are the following two:
- Fix the weights of the pre-trained model:
- First, the weights of the original large-scale model are fixed as they are. In other words, the weights of the original model are not changed.
- Inject low-rank matrices:
- Instead of fixed weights, new trainable matrices (low-rank matrices) are added to each layer. And only these low-rank matrices are trained.
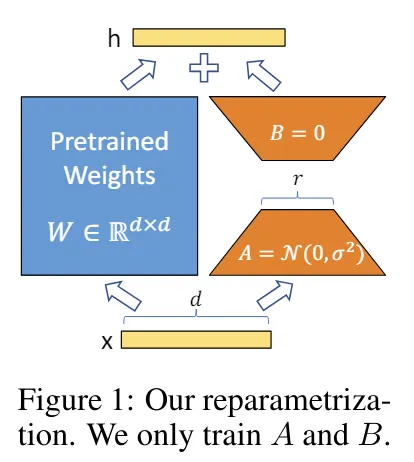
Low-rank matrices are added to the layers so that the calculation becomes as follows:
- Let the original weight matrix be (W).
- Prepare new trainable matrices (A) and (B).
- For the input vector (x), the original calculation is (W times x), but low-rank matrices are added so that it becomes (W times x + (A times B) times x).
LoRA in Stable Diffusion
Overview of Stable Diffusion LoRA
LoRA (Low-Rank Adaptation) in Stable Diffusion is mainly recognized as a method for changing art styles. However, the benefits of LoRA are not limited to that. LoRA makes it easy to create your own dedicated model and enables efficient tuning. Since LoRA training can be executed with dozens of images and a PC with moderate specs, significant cost reduction is possible compared to fine-tuning. Conventional fine-tuning required thousands of images and tens of GB of VRAM, but LoRA significantly reduces that burden.
Regarding the model architecture, Stable Diffusion is mainly based on the UNet structure, and LoRA adapts by adding low-rank parameters to specific layers of UNet. This allows for efficient tuning without significantly changing the structure of the original model. Specifically, applying LoRA to the encoder, decoder, cross-attention layers, etc., improves the quality and adaptability of image generation.
Derivatives of LoRA
Derivatives of LoRA that can be used in Stable Diffusion include LoCon, LoHA, LoKr, etc.
Lora beYond Conventional methods, Other Rank adaptation Implementations for Stable diffusion. - KohakuBlueleaf/LyCORIS

| Indicator | Full | LoRA | LoHa | LoKr low factor | LoKr high factor |
|---|---|---|---|---|---|
| Fidelity | ★ | ● | ▲ | ◉ | ▲ |
| Flexibility | ★ | ● | ◉ | ▲ | ● |
| Diversity | ▲ | ◉ | ★ | ● | ★ |
| Size | ▲ | ● | ● | ● | ★ |
| Training Speed (Linear) | ★ | ● | ● | ★ | ★ |
| Training Speed (Convolution) | ● | ★ | ▲ | ● | ● |
★ > ◉ > ● > ▲ [> means better and smaller size is better]
*Flexibility: Related to the ability to generate images not included in the training set, or the ability to combine multiple concepts regardless of training.
Conclusion
LoRA (Low-Rank Adaptation) opens up new possibilities for machine learning by enabling efficient tuning of large-scale models and significantly reducing computational costs and memory usage. Especially in image generation models like Stable Diffusion, it demonstrates its value not only for changing art styles but also as a means to easily create high-quality dedicated models. With the introduction of LoRA, more people will be able to use advanced models, and innovative applications will likely be born one after another.
If you want to actually try LoRA, the following article introduces the procedure using ComfyUI, so please check it out.

>-
In addition, papers related to Stable Diffusion that I have read are summarized in the following article, so please use it if you are interested.
Stable Diffusion関連の論文解説記事のリンク集。画像生成・動画生成の基礎モデルから応用技術まで論文ベースで解説。