Previously I tried to run the official demo of Stable Video Diffusion and got an out of memory error, but I was able to run it by another method so I will introduce it. Incidentally for my own technical understanding, I will include explanation of what kind of method it is.
Previous article ↓

>-
What is Stable Video Diffusion
It is a model extended to generate videos based on Stable Diffusion model. In terms of learning method and model architecture, devised specifically for video, succeeding in creating a model possessing knowledge not only in spatial direction but also time direction.

We present Stable Video Diffusion - a latent video diffusion model for high-resolution, state-of-the-art text-to-video and image-to-video generation. Recently, latent diffusion models trained for 2D image synthesis have been turned into generative video models by inserting temporal layers and finetuning them on small, high-quality video datasets. However, training methods in the literature vary widely, and the field has yet to agree on a unified strategy for curating video data. In this paper, we identify and evaluate three different stages for successful training of video LDMs: text-to-image pretraining, video pretraining, and high-quality video finetuning. Furthermore, we demonstrate the necessity of a well-curated pretraining dataset for generating high-quality videos and present a systematic curation process to train a strong base model, including captioning and filtering strategies. We then explore the impact of finetuning our base model on high-quality data and train a text-to-video model that is competitive with closed-source video generation. We also show that our base model provides a powerful motion representation for downstream tasks such as image-to-video generation and adaptability to camera motion-specific LoRA modules. Finally, we demonstrate that our model provides a strong multi-view 3D-prior and can serve as a base to finetune a multi-view diffusion model that jointly generates multiple views of objects in a feedforward fashion, outperforming image-based methods at a fraction of their compute budget. We release code and model weights at https://github.com/Stability-AI/generative-models .

Learning Method
First explaining learning method, they performed learning in following 3 stages.
- Training to create image from text (text-to-image pretraining)
- Train normal Stable Diffusion model with dataset of pairs of text and corresponding image.
- Basic training for video (video pretraining)
- Add layers (temporal layer) to model to add temporal information (continuity between frames) to model generating image from text
- Train model with collected videos
- Finetuning for high-quality video (high-quality video finetuning)
- Select high quality videos, remove scenes with little movement or clips with too much text.
- Finetune model using dataset of high quality videos
Architecture
Next I explain how the model extended Stable Diffusion model for video. As mentioned a bit in learning method section, Temporal Layer, a layer to learn spatial information, is added to Stable Diffusion model during learning. Temporal Layer seems to apply 3D convolution and attention along time axis. It seems to be proposed in the following paper, so read the paper below if interested.
Latent Diffusion Models (LDMs) enable high-quality image synthesis while avoiding excessive compute demands by training a diffusion model in a compressed lower-dimensional latent space. Here, we apply the LDM paradigm to high-resolution video generation, a particularly resource-intensive task. We first pre-train an LDM on images only; then, we turn the image generator into a video generator by introducing a temporal dimension to the latent space diffusion model and fine-tuning on encoded image sequences, i.e., videos. Similarly, we temporally align diffusion model upsamplers, turning them into temporally consistent video super resolution models. We focus on two relevant real-world applications: Simulation of in-the-wild driving data and creative content creation with text-to-video modeling. In particular, we validate our Video LDM on real driving videos of resolution 512 x 1024, achieving state-of-the-art performance. Furthermore, our approach can easily leverage off-the-shelf pre-trained image LDMs, as we only need to train a temporal alignment model in that case. Doing so, we turn the publicly available, state-of-the-art text-to-image LDM Stable Diffusion into an efficient and expressive text-to-video model with resolution up to 1280 x 2048. We show that the temporal layers trained in this way generalize to different fine-tuned text-to-image LDMs. Utilizing this property, we show the first results for personalized text-to-video generation, opening exciting directions for future content creation. Project page: https://research.nvidia.com/labs/toronto-ai/VideoLDM/
Steps to generate video with ComfyUI
Install ComfyUI
Please refer to this article.
>-
Create Workflow
I will use what is provided officially as is this time.
- Download and Load workflow
- This time I use workflow provided by comfyUI official.
-
Video Examples
Examples of ComfyUI workflows
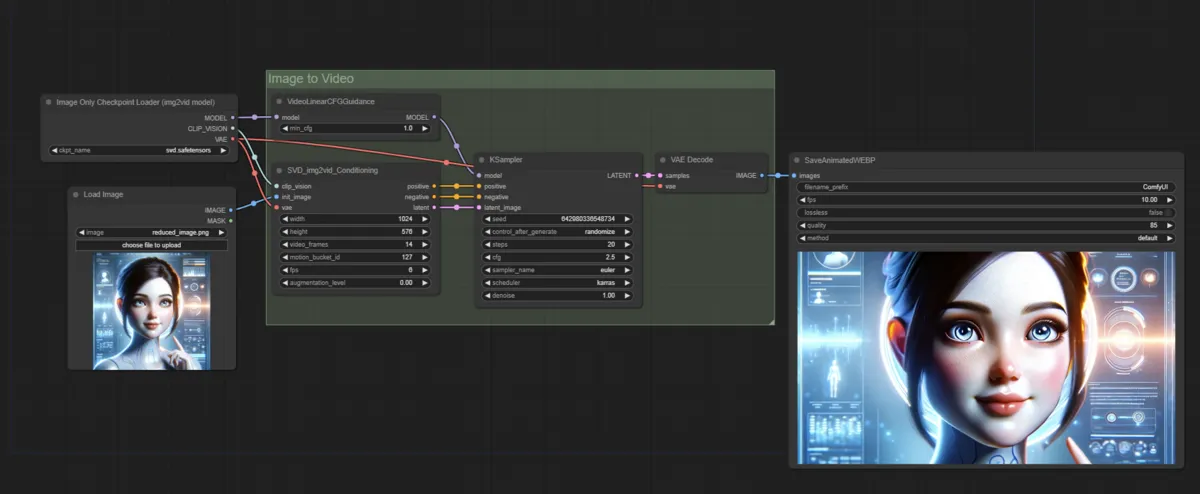
Download and Place Model
- Download checkpoint for SVD
- Download either for normal or XT and place in
/ConfyUI/models/checkpoint -
stabilityai/stable-video-diffusion-img2vid at main
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co -
stabilityai/stable-video-diffusion-img2vid-xt at main
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
- Download either for normal or XT and place in



Generate
- Set checkpoint downloaded earlier to
Checkpoint Loadernode- If not appearing, I think it will appear in pull-down if you refresh screen.
- Rest is OK if you adjust parameters and execute Queue Prompt.
Generation Result

Conclusion
Since movement cannot be specified, it feels completely like a game of luck. Since target video cannot be produced and picture collapses if trying to output long duration, currently I feel AnimateDiff is more suitable for content creation. Since you can customize specification of motions etc. I want to wait with expectation not for image2video but for text2video to be released.
If you want to try other methods related to video generation, please utilize the link collection below.
>-









