Introduction
[!NOTE] This article was generated by feeding my chaotic, personal reading notes of this massive textbook into an AI to restructure them into a readable blog post.
When a performance failure strikes, guessing parameters or rebooting and praying is amateur hour. Our first move should be to coldly observe what’s happening internally—without imposing a destructive load (perturbation) on the system.
In this post, we’re covering “Chapter 4: Observability Tools,” the weapons we’ll be using to dissect CPU, memory, and networking in the upcoming chapters.
Tools aren’t magic boxes that spit out answers. If you don’t understand where in the kernel a tool is pulling its data from—the underlying mechanisms and overhead—you’ll end up being deceived by the output or, worse, freezing your production environment. Here’s a survival cheat sheet for the foundations of observability.
1. Saving Production: “Crisis Tools”
Realizing you don’t have the right tools installed while your production system is on fire is the ultimate nightmare. Once a server is hitting a performance wall, installing new packages can take an agonizingly long time, extending the crisis.
- You should have your “Crisis Tools” pre-baked into your base images.
- Classic
sysstat(iostat, mpstat, pidstat, sar) andprocps(vmstat, top) are givens, but for modern Linux analysis,linux-tools-common(perf),bcc-tools, andbpftraceare absolute essentials.
2. The Four Quadrants: What data are you looking at?
Performance tools can be categorized into four quadrants based on their data collection approach: “System-wide vs. Per-process” and “Fixed Counters vs. Event-based.” Always be conscious of which angle you’re viewing the system from.
- Fixed Counters (vmstat, iostat, etc.): These just read counters maintained by the kernel, so overhead is extremely low. However, they don’t tell you the “why” (no code paths).
- Profiling and Tracing: “Profiling” (like
perf) takes periodic snapshots (e.g., 99Hz) to paint a general picture. “Tracing” (likebpftrace) records every single occurrence of an event. - Monitoring (sar, etc.): Tools like
sar(System Activity Reporter) are for recording and archiving counters over time to review historical patterns and peaks.
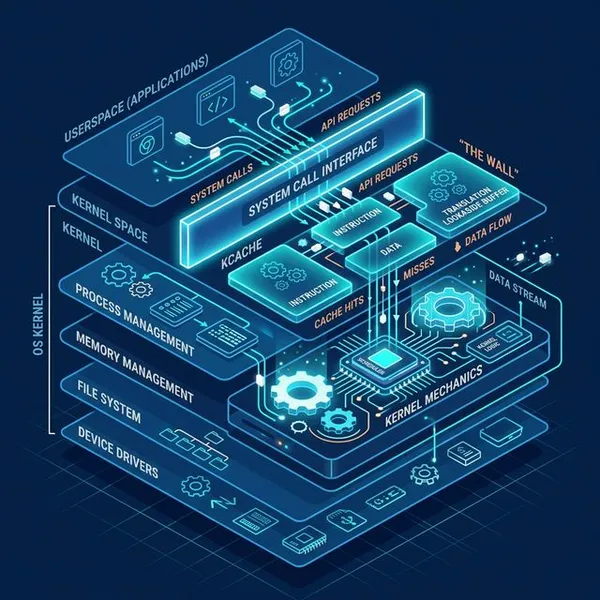
3. Windows into the Kernel: Information Sources
Tools aren’t magic; they’re just pulling information from interfaces provided by the OS.
- The /proc Trap: Tools like
topread this pseudo-filesystem. It’s convenient, but on systems with tens of thousands of processes, just parsing the text files in/proccan causetopitself to devour the CPU. Not exactly what you want during a crisis. - Delay Accounting: A powerful Linux feature that accurately records, in nanoseconds, how long a thread spent waiting for the scheduler, block I/O, or swapping.
- PMCs (Hardware Counters): These are internal CPU registers that expose hardware-level truths—like cache misses, instruction counts, and memory stall cycles—that software tools can never see.
4. Static vs. Dynamic Instrumentation
To track specific operations in apps or the kernel, you need to set up observation points (instrumentation).
- Static Instrumentation (Tracepoints / USDT): These are pre-defined points embedded in the source code of the kernel (tracepoints) or user-space apps (USDT) by developers. They offer low overhead and stability. Languages/runtimes like JVM and Node.js have USDT probes.
- Dynamic Instrumentation (kprobes / uprobes): The ultimate magic. You can on-demand insert breakpoints into running kernel functions (kprobes) or application functions (uprobes) to rewrite instructions and monitor them. It’s the “last resort” for problems no other tool can solve, but use it with caution as APIs can be unstable.
Conclusion
Reading this chapter makes it crystal clear how commands we use every day, like top and iostat, actually aggregate information from the kernel.