Blender x ComfyUI:ComfyUI-BlenderAI-nodeの導入方法
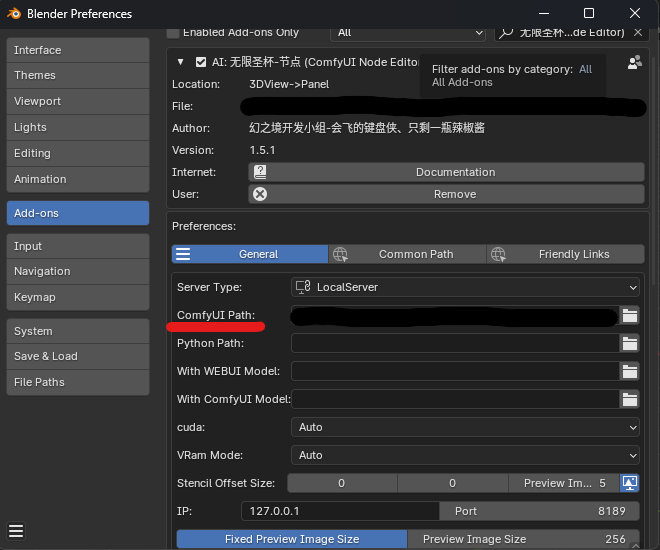
ComfyUI-BlenderAI-nodeの導入手順を簡単に解説します。

ComfyUI-BlenderAI-nodeの導入手順を簡単に解説します。

KritaのStableDiffusion拡張を使用して、落書きから画像をリアルタイム生成する手順を説明します。

akuma.aiのような落書きから画像生成する機能をローカル環境で再現できるかをComfyUIで試してみました。手順や必要な拡張機能、モデルの設定方法を詳しく解説し、生成結果も公開しています。

この記事では、ComfyUIを使ってStable Diffusion 3で画像を生成する方法をステップバイステップで解説します。ComfyUIの導入、必要なモデルのダウンロードと配置、ワークフローのインポート方法を詳しく説明し、実際に生成した画像の評価とともに全体的な使用感をお伝えします。
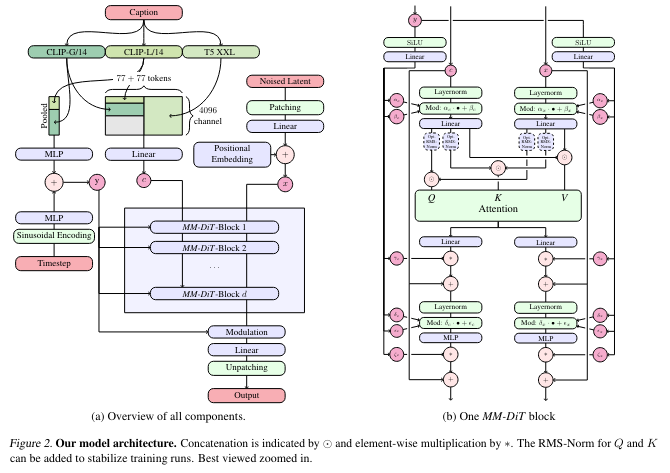
Stable Diffusion 3は、CLIPとT5を組み合わせた新しいText Encoderや、DiTアーキテクチャの導入で大幅に進化しました。新しいノイズスケジューラーにより、生成性能が向上し、txt2imgで最先端モデルを超える性能を実現。簡単に論文の内容を説明します。

この記事では、ComfyUIを使用し、ESRGANで画像をアップスケールする具体的な手順と生成結果を紹介します。

この記事では、ComfyUIを使って、Stable DiffusionのOutpaintを行う手順を紹介します。Outpaintを使用することで、自分で描かずとも、画像の外側に新しい内容を追加することができます。

ComfyUIを使ったStableDiffusionによるInpaint技術の手順を詳しく解説。画像の特定部分をマスクし、新たな要素を追加する方法をステップバイステップで説明します。生成結果も掲載しています。