ControlNetは、既存のStable Diffusionモデルを拡張し、人物の姿勢などの空間的な条件付けを学習できるようにする画期的な技術です。どのような手法でこれを実現しているのかを図を交えながら説明していきます。
Contents
ControlNetについて

ControlNetの概要
ControlNetは既存の学習済みtext2imageモデルを拡張し、空間的な条件付け(今回でいうと人物の姿勢)を学習できるようにする手法です。ベースモデルに空間的な条件付けを学習するためのControlNetモジュールを追加し、姿勢を学習できるようにしています。
ControlNetモジュール
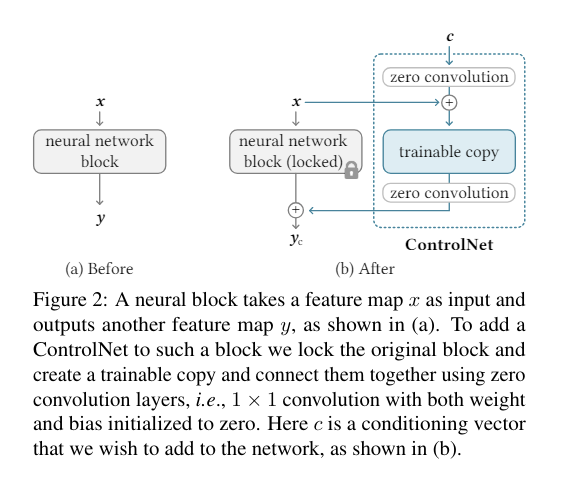
下に論文から引用してきたControlNetモジュールのアーキテクチャを貼っておきます(aがControlNet追加前、bが追加後)。
元の学習済みモデルは重みを固定し、拡張した部分のみを、姿勢を覚えさせるために学習させます。学習済みモデルが持つ重みをControlNetの初期値(重み)とすることで、効率的に学習ができます。
(図にあるZero Convolusionについては、Appendixの方で説明します)
最終的なアーキテクチャ
以下に論文から引用してきたモデル(ベースモデル部分のアーキテクチャ)を置いておきます。
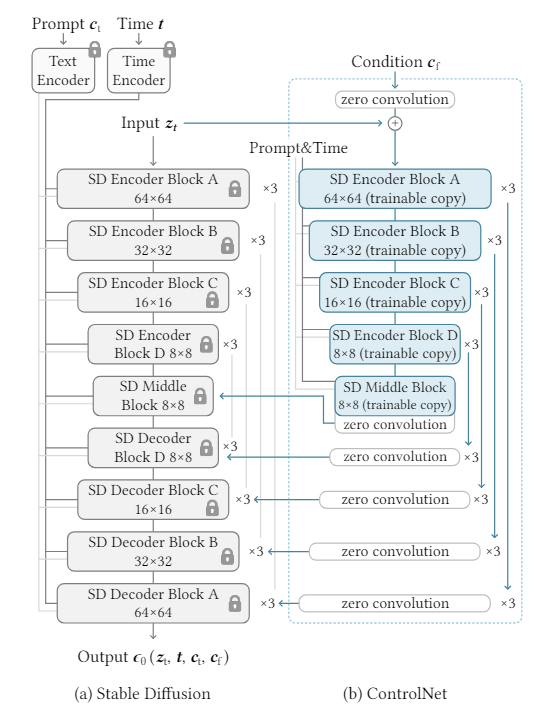
引用: Lvmin Zhang, Anyi Rao, Maneesh Agrawala, 2023, Adding Conditional Control to Text-to-Image Diffusion Models, https://arxiv.org/abs/2302.05543
これをStable Diffusion全体で表すと以下のようなアーキテクチャになります。
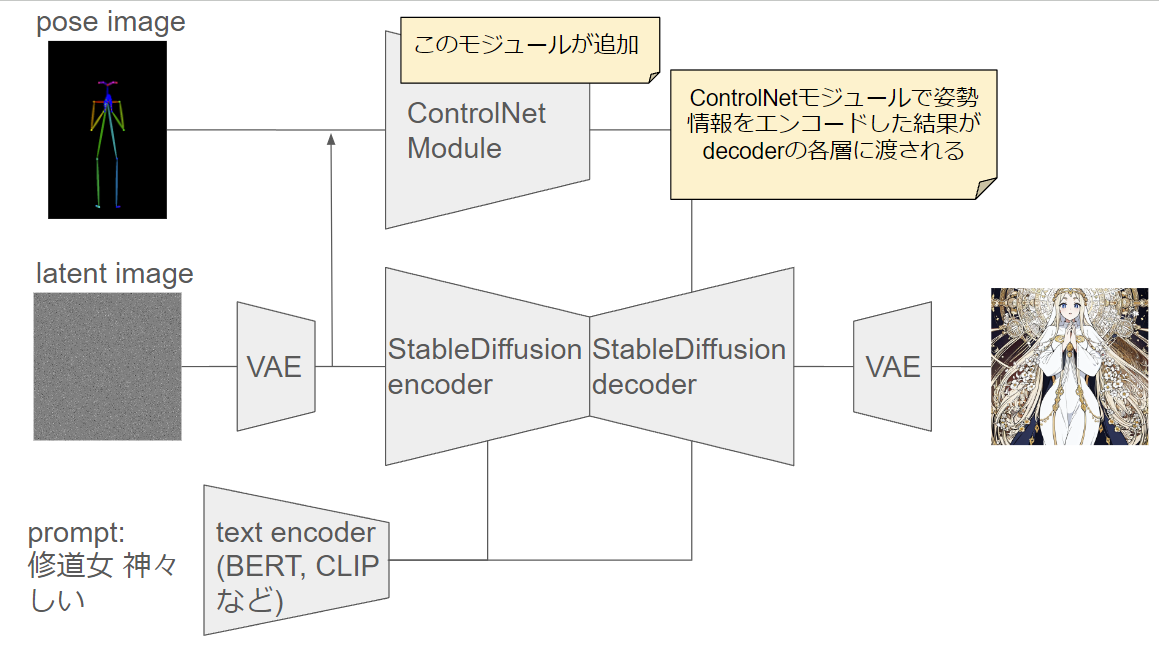
ControlNet適用後のアーキテクチャ
最後に
ControlNetは、Stable Diffusionモデルに姿勢制御機能を加えることで、画像生成技術に新たな可能性をもたらします。Zero Convolutionを活用して安定した学習プロセスを実現することで、より精度の高い画像生成が可能となります。この記事で紹介した技術を活用することで、より高度な画像生成モデルを構築できるようになるでしょう。
ControlNetを実際に使用する方法については以下の記事で説明しているので、余裕ある方は試してみてください。
Stable Diffusion周りで読んだ論文は以下の記事でまとめているので、興味ある方はぜひご活用ください。
Appendix
Zero Convolutionとは
もし畳み込み層の初期化が適切でない場合、学習時にモデルのパラメータが急激に変動することで、生成される画像に不規則なアーティファクト(望ましくないパターンや欠陥)が現れることがあります。こうした学習時のノイズは、勾配の収束を遅れさせるため効率が低下します。
こういった有害なノイズを防ぐためにControlNetモジュールではZero Convolutionが使用されています。Zero Convolutionは以下二点によりノイズを抑制します。
- ゼロ初期化
- パラメータがゼロから始まるため、学習の初期段階で大きな変動が発生しません。これにより、モデルが安定して学習を開始できます。
- 徐々に成長するパラメータ
- パラメータが徐々に成長することで、学習プロセスが安定し、ノイズの影響を最小限に抑えることができます。