【Stable Diffusion】ComfyUIを使って画像生成AIで遊んでみよう【IPAdapter編】

Stable DiffusionのIPAdapterで画像プロンプトを活用し、アートスタイルや構図を自由にコントロール。ComfyUIでの設定と使用方法を紹介します。

Stable DiffusionのIPAdapterで画像プロンプトを活用し、アートスタイルや構図を自由にコントロール。ComfyUIでの設定と使用方法を紹介します。
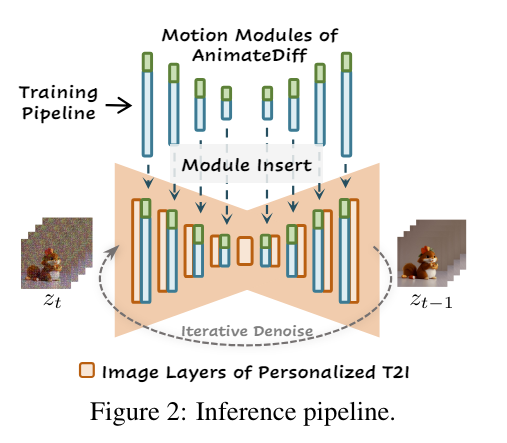
AnimateDiffは、Stable Diffusionモデルを拡張して動画生成を可能にする新技術です。その特徴であるDomain AdapterやMotion Moduleについて、そして高品質なアニメーション生成の仕組みを簡単に解説します。
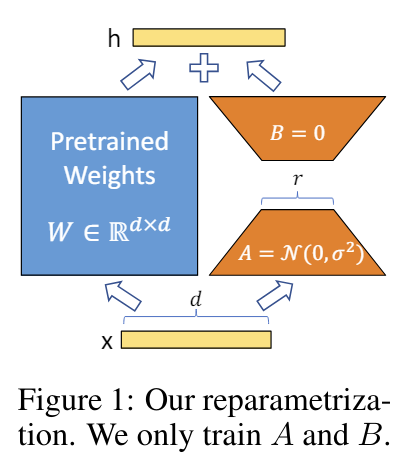
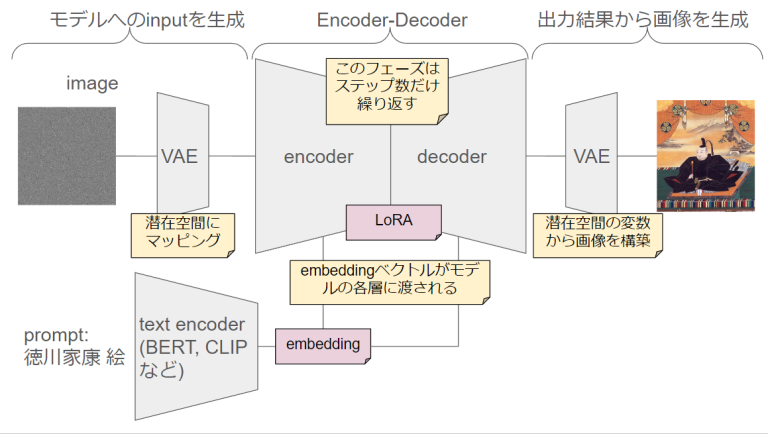
LoRAは、大規模なモデルに小さな層を追加し、計算コストを削減しながら高いパフォーマンスを実現します。その手法とメリットを簡単に紹介します。
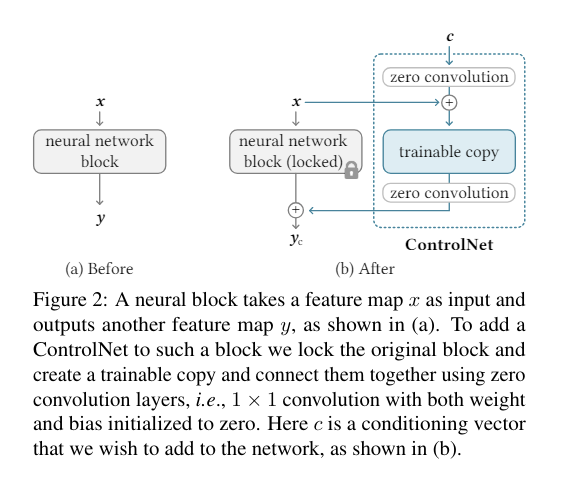
ControlNetはStable Diffusionモデルを強化し、姿勢を学習・制御できるようにします。この記事では、初心者向けにその基本概念を紹介します。
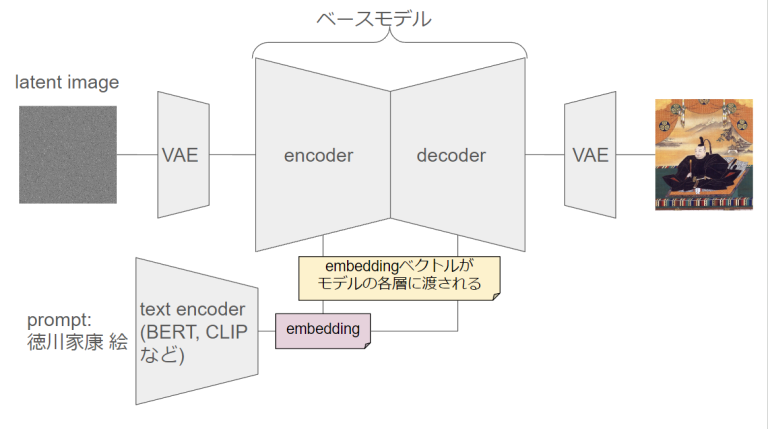
Textual Inversionは、プロンプトの言語ベクトルを通じてStable Diffusionの出力を制御する手法です。LoRAとの違いを比較しながら、初心者にも理解しやすい形でその仕組みと応用方法を紹介します。
この記事では、Stable Diffusionの画像生成モデルの仕組みを解説します。拡散モデルの基本概念からLatent Diffusion Models(LDM)の詳細まで、理論的背景と具体的なプロセスを説明。なんとなくで使ってるその技術、どうやって動いてるか知りたくないですか?

ComfyUIを使ってStable Diffusionでembeddingを使用する方法を紹介します。好きなembeddingを使用した実例とその効果の違いを画像で比較し、より良い生成結果を得るためのポイントも解説します。
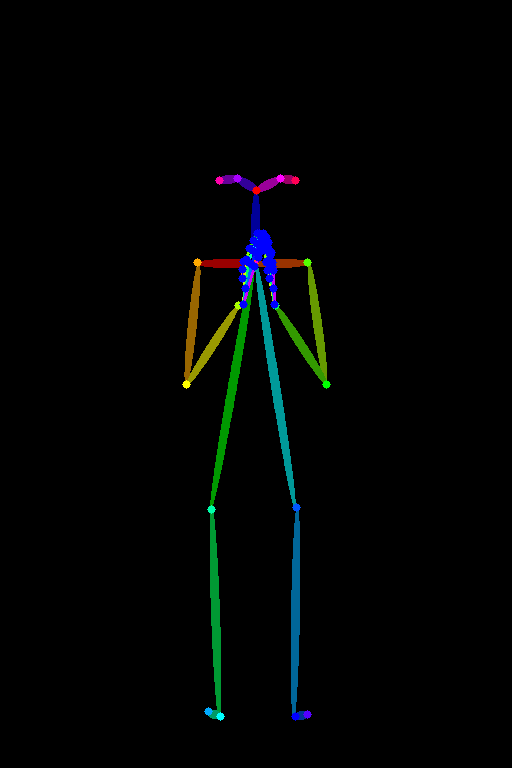
この記事では、Stable Diffusionモデルを拡張し、人物の姿勢を指定して画像生成を行う手法「ControlNet」について解説します。ControlNetの仕組みやアーキテクチャの詳細を説明し、実際にComfyUIを使ってポーズ指定した画像を生成する手順を紹介します。初心者でもわかりやすい具体的なステップを示し、効率的に高品質な画像を生成する方法を学びましょう。