株でできるだけ分散投資したい場合、どの分野(セクター)にどれだけ投資すれば良いか迷いますよね???
全分野それぞれ買えば良いやんという人もいるかもですが、それでは芸がないですしお金もかかってしまいます。
このときに使えるのが相関分析です。セクタ別に分かれているとはいえど相関はあるため、相関が低いセクタを選択して買うことで最大限のリスク分散効果が得られます。
今回はそれを計算するpythonスクリプトを書いてみたので、ぜひ使っていただけると幸いです。といっても簡単なものなので、考え方だけ読んで自分で書いてみるのも学びになるかもしれません。
基本的な考え方
相関とは
2つ以上の変数がどの程度関連しているかを示す統計的な関係を示します。
1つの変数が変化するときに、もう1つの変数がどのように変化するかを測定します。もう一つの変数が増加することが多ければ正の相関、減少することが多ければ負の相関になります。
相関係数とは
相関係数は-1から1までの値を取り、1に近いほど強い正の相関、-1に近いほど強い負の相関、0に近いほど相関がないことを示します。
計算方法は以下です。
\[
r = \frac{\sum_{i=1}^{n} (x_i – \bar{x})(y_i – \bar{y})}{\sqrt{\sum_{i=1}^{n} (x_i – \bar{x})^2} \cdot \sqrt{\sum_{i=1}^{n} (y_i – \bar{y})^2}}\
\]
\[
\begin{align}
&r: \text{相関係数} \\
&n: \text{データの数} \\
&x_i: \text{x の i 番目のデータ} \\
&\bar{x}: \text{Xの平均} \\
\end{align}
\]
相関をどう活用するか
正の相関があるセクタを選んで買ってしまうと、片方の株価が下がった時にもう片方も下がってしまう可能性が高いということになります。これはあるファクタに対するリスクが高い状態と言えます。
逆も然りで、負の相関があるセクタを選んで買ってしまうと、片方の株価が上がった場合にもう片方は下がるのでリターンが圧縮されてしまいます。
そのため、無相関に近い(独立している)セクタを選ぶことで、リスク分散しながらリターンも得ようという話になります。
Pythonスクリプト
各セクタの株価を全部使用して分析するのは骨が折れるため、ETFのデータで分析します。収益率は30日の期間で計算します。
※日本株全体にかかるファクターリターンを除くため、ファクターモデルを使ってTOPIXから受けるリターンを除いています。
import yfinance as yf
import pandas as pd
import japanize_matplotlib
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np
from sklearn.linear_model import LinearRegression
# 簡単のためfactorは一つのみ
def calc_beta(target_return, factor_return):
# データを整形
data = pd.DataFrame({
'TargetReturn': target_return,
'FactorReturn': factor_return,
}).dropna()
# 回帰分析の準備
X = data[['FactorReturn']] # 説明変数
y = data['TargetReturn'].values # 目的変数
# 回帰分析を実施
model = LinearRegression()
model.fit(X, y)
beta = model.coef_[0]
return beta
def calc_unique_return(target_return, factor_return):
beta = calc_beta(target_return, factor_return)
unique_return = target_return - beta*factor_return
return unique_return
# ETFのティッカーシンボルの辞書を作成
tickers = {
"TOPIX-17食品": "1617.T",
"TOPIX-17エネルギー資源": "1618.T",
"TOPIX-17建設・資材": "1619.T",
"TOPIX-17素材・化学": "1620.T",
"TOPIX-17医薬品": "1621.T",
"TOPIX-17自動車・輸送機": "1622.T",
"TOPIX-17鉄鋼・非鉄": "1623.T",
"TOPIX-17機械": "1624.T",
"TOPIX-17電機・精密": "1625.T",
"TOPIX-17情報通信・サービスその他": "1626.T",
"TOPIX-17電力・ガス": "1627.T",
"TOPIX-17運輸・物流": "1628.T",
"TOPIX-17商社・卸売": "1629.T",
"TOPIX-17小売": "1630.T",
"TOPIX-17銀行": "1631.T",
"TOPIX-17金融(除く銀行)": "1632.T",
"TOPIX-17不動産": "1633.T",
"TOPIX": "^TOPX"
}
# 株価データを取得
data = yf.download(list(tickers.values()), start="2009-08-15", end="2024-8-15")['Adj Close']
data.columns = list(tickers.keys())
# 対数収益率に変換
returns = np.log(data / data.shift(30))
# TOPIXのデータだけ抜き出す
topix_return = returns["TOPIX"]
returns = returns.drop(columns=["TOPIX"])
# ファクターモデルを用いて日本株全体にかかるファクターリターンを引く
unique_returns = returns.apply(calc_unique_return, factor_return = topix_return)
# 相関係数行列を計算
correlation_matrix = unique_returns.corr()
# Seabornのheatmapで可視化
plt.figure(figsize=(16, 12))
sns.heatmap(correlation_matrix, annot=True, cmap='coolwarm', fmt=".2f", vmin=-1, vmax=1)
plt.title("TOPIX-17 Sectors Correlation Matrix")
plt.savefig("result2.png")
#plt.show()[20240831追記]
ベータ計算の説明変数と目的変数が逆だったため修正しました。実行結果も置き換え済です。
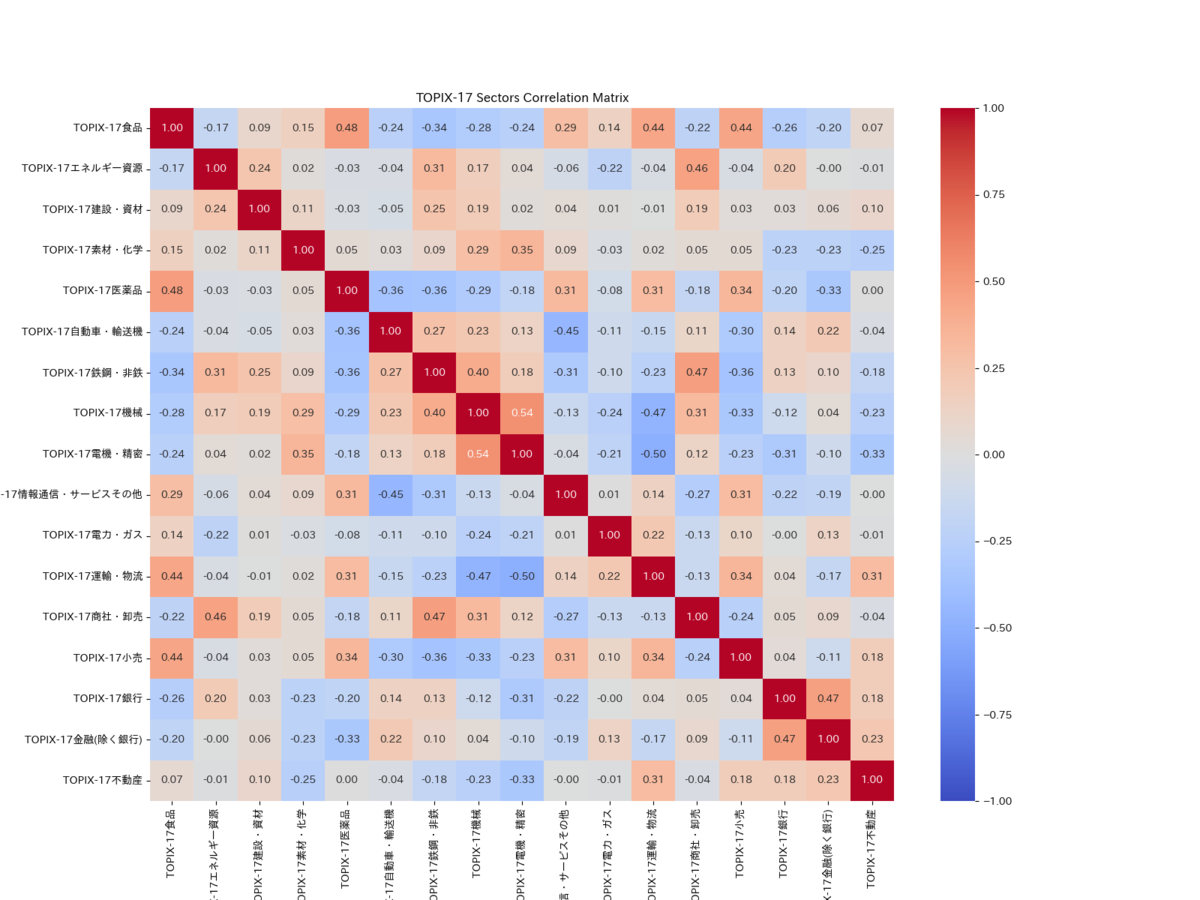
実行結果
実行結果はヒートマップとして出力されます。この中から相関係数が0に近いものを選ぶことになります。
最後に
今回はセクタ間の相関分析をpythonで行う方法について簡単に解説しました。今回はセクタ間で分析しましたが、株/債券、新興国/先進国、REIT、コモディティ、為替などなど色々な分類方法で活用できる考え方なので、自分のポートフォリオに合わせてカスタマイズして使用してみると良いと思います。注意点としては、配当、優待などは加味されていないので各セクタの中で配当が良いものを選ぶなり、別枠として考えるなりしてください。
最後に付け加えるとすると、これ自体は考え方の一つに過ぎないので、単体で運用するよりかはその他テクニックを組み合わせるなりして自分に合った選び方を作ると良いでしょう。
ではまた次の記事で。バイバイ