以前Stable Video Diffusionの公式デモを実行しようとしてメモリ不足エラーになってたのですが、他の方法で実行することができたので紹介しようと思います。ついでに僕自身の技術理解もかねてどういう手法なのかも説明を入れておきます。
以前の記事は↓
Contents
Stable Video Diffusionとは
Stable Diffusionのモデルをベースに動画が生成できるように拡張したモデルです。学習方法、モデルのアーキテクチャの面において動画用に工夫を施し、空間方向だけでなく時間方向の知識を持ったモデルの作成に成功しました。

学習方法
まず学習方法について説明すると次の3段階で学習を行ったとのことです。
- テキストから画像を作るための訓練(text-to-image pretraining)
- テキストとそれに対応する画像のペアのデータセットで通常のStable Diffusionモデルを訓練します。
- ビデオのための基本的な訓練(video pretraining)
- テキストから画像を生成するモデルに時間的な情報(フレーム間の連続性)を追加するために、モデルに層(temporal layer)を追加します
- モデルを収集したビデオで訓練します
- 高品質なビデオのための微調整(high-quality video finetuning)
- 高品質なビデオを選定し、動きの少ないシーンやテキストが多すぎるクリップを除去します。
- 高品質なビデオのデータセットを使ってモデルを微調整します
アーキテクチャ
次にモデルがStable Diffusionモデルをどうやって動画用に拡張したかを説明します。学習方法の項でも少し出てきましたがStable DIffusionモデルにTemporal Layerという空間方向の情報を学習するための層を学習途中に追加します。Temporal Layerは、3次元畳み込みと時間軸に沿ったattentionを適用しているようです。以下の論文で提唱されたもののようなので、気になる方は下の論文を読んでみてください。
ComfyUIで動画生成する手順
ComfyUIのインストール
こちらの記事を参照ください。
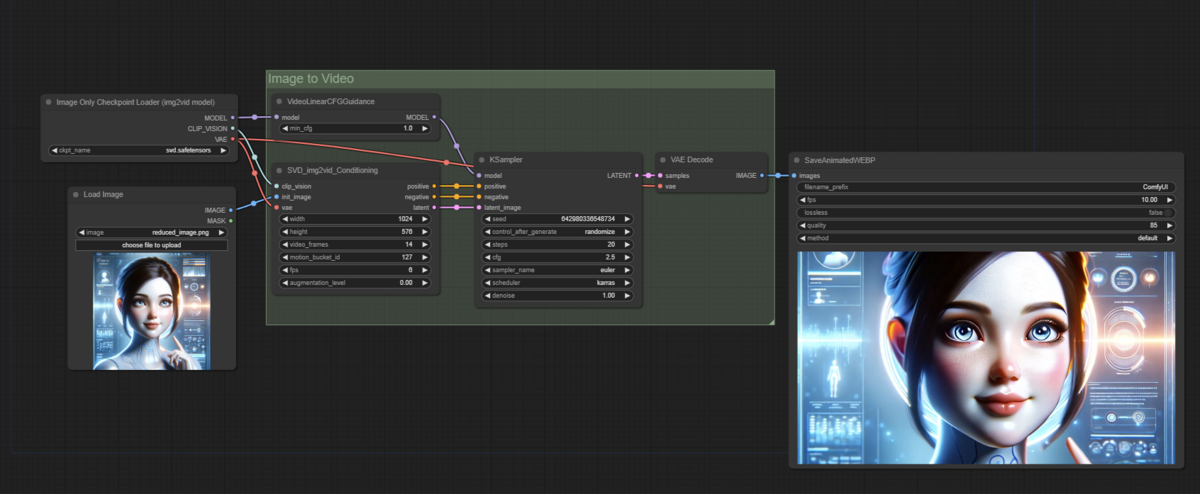
ワークフローの作成
今回は公式で提供されているものをそのまま使います
- workflowのダウンロードとLoad
- 今回はcomfyUI公式が提供しているワークフローを使います。
- Video Examples | ComfyUI_examples
モデルのダウンロードと配置
- SVD用チェックポイントをダウンロードしてくる
- 通常とXT用のどちらかダウンロードして
/ConfyUI/models/checkpointに置く - stabilityai/stable-video-diffusion-img2vid at main
- stabilityai/stable-video-diffusion-img2vid-xt at main
- 通常とXT用のどちらかダウンロードして
生成する
Checkpoint Loaderノードに先ほどダウンロードしたチェックポイントを設定する- 出ない方は画面を更新すればプルダウンに表示されると思います。
- 後はパラメータを調整してQueue Promptを実行すればOKです。
生成結果

最後に
動きは指定できないので完全な運ゲーな感じですね。狙った動画は出せないのと長尺で出そうとすると絵崩れするので、現状だとAnimateDiffの方がコンテンツ作成には向いてるのかなって感じがします。動作の指定などカスタマイズができたりするので。image2videoでなく、text2videoが公開されるのを期待して待ちたいと思います。
動画生成に関連する他の手法を試したい方は下記のリンク集をぜひご活用ください。