LoRA (Low Rank Adaptation) は、現代の機械学習やディープラーニングの分野で急速に注目を集めている革新的な手法です。
Stable Diffusionの世界では、LoRAは効率的な学習手法というより、絵柄を変えるための技術として認知されています。しかし、LoRAの真の価値はそれだけに留まりません。本来、LoRAは大規模なモデル、特にGPTのような億単位のパラメーターを持つトランスフォーマーモデルを効率的にチューニングするために設計された手法です。その最大の特徴は、従来の方法に比べて学習にかかる計算コストとメモリ使用量を大幅に削減できる点にあります。
この記事では、LoRAの基本原理からその具体的な応用例までをわかりやすく解説します。まず、LoRAがどのようにして大規模モデルのチューニングを効率化するのか、そのメカニズムを詳しく見ていきます。次に、LoRAが実際にどのように使われているのか、特にStable Diffusionにおける応用例を通じて、その多岐にわたるメリットを探ります。
Contents
LoRAとは

LoRAの概要
LoRAはLow Rank Adaptationの略で、少ない計算コストで大きいモデル(例えばTransformer)のチューニングを行おうとする手法です。GPTなど巨大なモデルのファインチューニングを行うのは計算コスト的に膨大です。そのため、学習済みの大きなモデルに小さな層を後から追加し、元の重みを固定しながら追加した小さな層の重みのみを学習します。これにより、必要な計算量やメモリを大幅に削減し、効率的に特定のタスクに適応させることができます。
LoRAを使うメリット
| メリット | 説明 |
|---|---|
| メモリ効率の向上 | モデル全体をファインチューニングする代わりに、少ないパラメータで適応が可能。メモリ使用量が大幅に削減され、軽量なデバイスでも動作が可能。 |
| 高速なトレーニング | パラメータ数が少ないため、トレーニング時間が短縮される。高速なプロトタイプ作成と実験が可能。 |
| 柔軟な適応 | 様々なタスクやドメインに迅速に適応可能。カスタムタスクに対する精度向上が期待できる。 |
| モデルの再利用 | 既存の大規模なモデルをベースにして、追加トレーニングのみで適応可能。モデルの再利用性が向上し、コスト効率が高まる。 |
| スケーラビリティ | 小規模から大規模までのデータセットに対して柔軟に対応可能。大規模モデルの適応が容易。 |
| パフォーマンスの向上 | 適応後のモデルは、元のモデルと同等以上のパフォーマンスを発揮することが多い。特定のタスクに対して最適化されるため、実用性が高い。 |
| 低リソース環境への適応 | 限られた計算リソースでも効果的に利用できる。デバイスやクラウド環境を問わずに展開が可能。 |
LoRAの手法
上でも書きましたが、この手法のポイントとしては以下の二点です。
- 事前学習済みモデルの重みを固定:
- まず、元の大規模モデルの重みはそのまま固定します。つまり、元のモデルの重みは変更されません。
- 低ランク行列を注入:
- 固定した重みの代わりに、各層に新しい学習可能な行列(低ランク行列)を追加します。そしてこの低ランク行列のみを学習します。
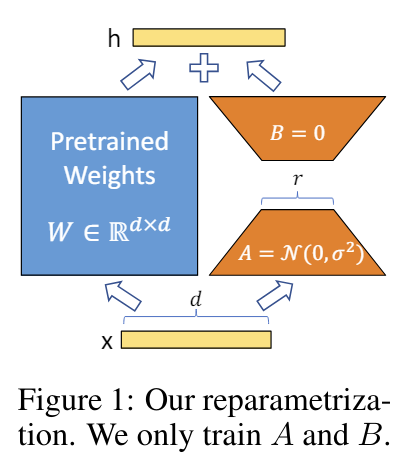
低ランク行列は以下の計算になるように層へ追加されます。
- 元の重み行列を (W)とします。
- 新しい学習可能な行列 (A)と(B)を用意します。
- 入力ベクトル (x)に対して、元の計算は(W times x)ですが、これを(W times x + (A times B) times x)となるように低ランク行列を追加します。
Stable DiffusionにおけるLoRA
Stable Diffusion LoRAの概要
Stable DiffusionにおけるLoRA (Low-Rank Adaptation) は、主に絵柄を変える手法として認知されています。しかし、LoRAのメリットはそれだけにとどまりません。LoRAは自分専用モデルの作成を容易にし、効率的なチューニングを可能にします。数十枚の画像と適度なスペックのPCがあれば、LoRAの学習を実行できるため、ファインチューニングに比べて大幅なコスト削減が可能です。従来のファインチューニングでは数千の画像と数十GBのVRAMが必要でしたが、LoRAはその負担を大幅に軽減します。
モデルのアーキテクチャに関しては、Stable Diffusionは主にUNet構造をベースにしており、LoRAはUNetの特定の層に低ランクのパラメータを追加することで適応を行います。これにより、元のモデルの構造を大幅に変更することなく、効率的なチューニングが可能となります。具体的には、エンコーダー、デコーダー、クロスアテンション層などにLoRAを適用することで、画像生成の品質と適応力が向上します。
LoRAの派生系
Stable Diffusionで使えるLoRAの派生系として、LoCon, LoHA, LoKrなどがあります。

| 指標 | Full | LoRA | LoHa | LoKr low factor | LoKr high factor |
|---|---|---|---|---|---|
| Fidelity(精度) | ★ | ● | ▲ | ◉ | ▲ |
| Flexibility(柔軟性) | ★ | ● | ◉ | ▲ | ● |
| Diversity(多様性) | ▲ | ◉ | ★ | ● | ★ |
| サイズ | ▲ | ● | ● | ● | ★ |
| トレーニング速度(線形) | ★ | ● | ● | ★ | ★ |
| トレーニング速度(畳み込み) | ● | ★ | ▲ | ● | ● |
★ > ◉ > ● > ▲ [> means better and smaller size is better]
*柔軟性とは、トレーニングセットに含まれない画像を生成する能力や、トレーニングの有無にかかわらず複数の概念を組み合わせる能力に関連するものです。
最後に
LoRA (Low-Rank Adaptation) は、大規模モデルの効率的なチューニングを可能にし、計算コストとメモリ使用量を大幅に削減することで、機械学習の新しい可能性を切り開いています。特にStable Diffusionのような画像生成モデルにおいては、絵柄の変更だけでなく、自分専用の高品質なモデルを手軽に作成する手段として、その価値を発揮しています。LoRAの導入により、より多くの人々が高度なモデルを利用できるようになり、革新的なアプリケーションが次々と誕生することでしょう。
実際にLoRAを試したい場合は、以下の記事でComfyUIを使った手順を紹介しているので、ぜひ読んでみてください。
その他、Stable Diffusion周りで読んだ論文は以下の記事でまとめているので、興味ある方はご活用ください。