Stable Audio Openは著作権周りをクリアするためにフリー音源で学習されたStable Audioのモデルです。
そんなStable Audio Openが無償公開されたので、公式デモをローカルで実行してみました。
Contents
Requirements
- PyTorch 2.0 or later
- できればcudaが使用できるGPU(CPUだとかなり遅いです)
実行方法
手順1:HuggingFace周りのあれこれ
HuggingFaceでStable-Audio-Openの使用許可を取る
ログインが必要
アクセストークンの生成
ログイン後であれば↓のリンク先で生成可能

手順2:環境の準備とデモの実行
- python: 3.10.14を使用しました
- ローカルを汚したくない方はvenvなどを使って実行してください。
# 依存関係のインストール(リポジトリに入ってpip install . でも可能)
pip install stable-audio-tools
# その他自分の環境で追加インストールが必要だったもの
sudo apt install libsndfile1
sudo apt install nvidia-cuda-toolkit
pip install flash-attn
# hugging faceのcredentialを登録しておく
huggingface-cli login
# デモの実行
git clone https://github.com/Stability-AI/stable-audio-tools.git
python ./stable-audio-tools/run_gradio.py --pretrained-name stabilityai/stable-audio-open-1.0手順3:デモにアクセス
デモの実行が正常に完了するとURLが表示されるので、それにアクセスします。
おまけ:public URLが嫌だ
デフォルトで全世界からアクセス可能なpublic URLなるものが生成されるようになっています。
URLをネットワーク上に公開したくないって人はrun_gradio.pyのinterface.launch(18行目)で指定されているshareパラメーターをFalseに修正してください。
もしくはrun_gradio.pyのオプションでusername, passwordを指定してあげれば、Basic認証が入るようになります。
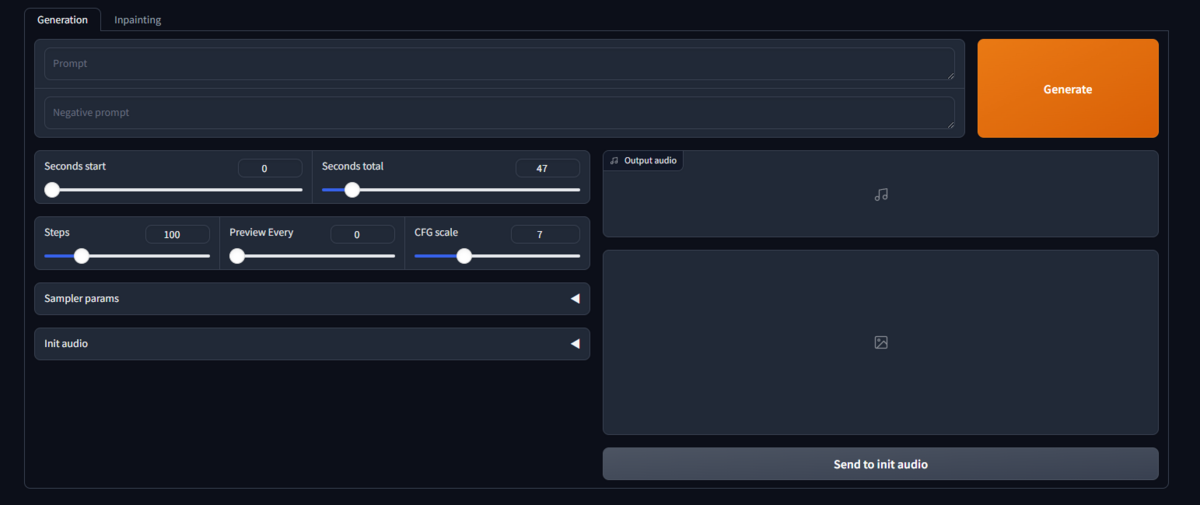
生成結果
positive
Trance, Progressive, Rock, EDM
negative
harsh, loud, chaotic, aggressive, dissonant, jarring, abrupt, noisy, overpowering, unsettling, atonal, disruptive
最後に
いかがだったでしょうか。音楽についてはあまり詳しくありませんが、素人なりに想像した感じのメロディが出てきたかなと思います。
stable-audio-toolsでは学習用のスクリプトも公開されているので、特定の楽曲に似たメロディを生成したい方はそちらも試してみると良いでしょう。(おそらくファインチューニングなので、メモリ・学習データとかは大量に必要)
自分的には無事生成出来て満足したので、今回はここまでにしておきます。